PointPillars: Fast Encoders for Object Detection from Point Clouds
PointPillarsとは2018年に提案された3D物体検出技術、または点群ニューラルネット技術です。
従来技術よりも高速かつ遥かに高精度で精度ー計算量のバランスが良く、現在多くの3D物体検出研究はPointPillarsを改良したものとなっております。
有名所ですと例えばAutowareに実装されていたりしますね。
課題

従来点群のみ使用したネットワークは精度は高いが低速で、点群を画像に投影するネットワークは高速だが 精度が低いという欠点があった。
提案
 狙いとしては点群の細かい情報量を失わないように情報量をエンコードし、疑似画像に変換する。その疑似画像を2D CNNで使用するような物体検出ネットワークに入力し、物体検出を行う。
この手法の進歩性は従来単純に点群を俯瞰画像といった疑似画像に投影し物体検出CNNに入力するだけでは点群の細かい情報量が失われてしまっていた。そこで点群を画像に投影するためのエンコードネットワークを用いることで点群情報を失わずに物体検出CNN(SSD)に入力データを与え高精度化を達成した。
狙いとしては点群の細かい情報量を失わないように情報量をエンコードし、疑似画像に変換する。その疑似画像を2D CNNで使用するような物体検出ネットワークに入力し、物体検出を行う。
この手法の進歩性は従来単純に点群を俯瞰画像といった疑似画像に投影し物体検出CNNに入力するだけでは点群の細かい情報量が失われてしまっていた。そこで点群を画像に投影するためのエンコードネットワークを用いることで点群情報を失わずに物体検出CNN(SSD)に入力データを与え高精度化を達成した。
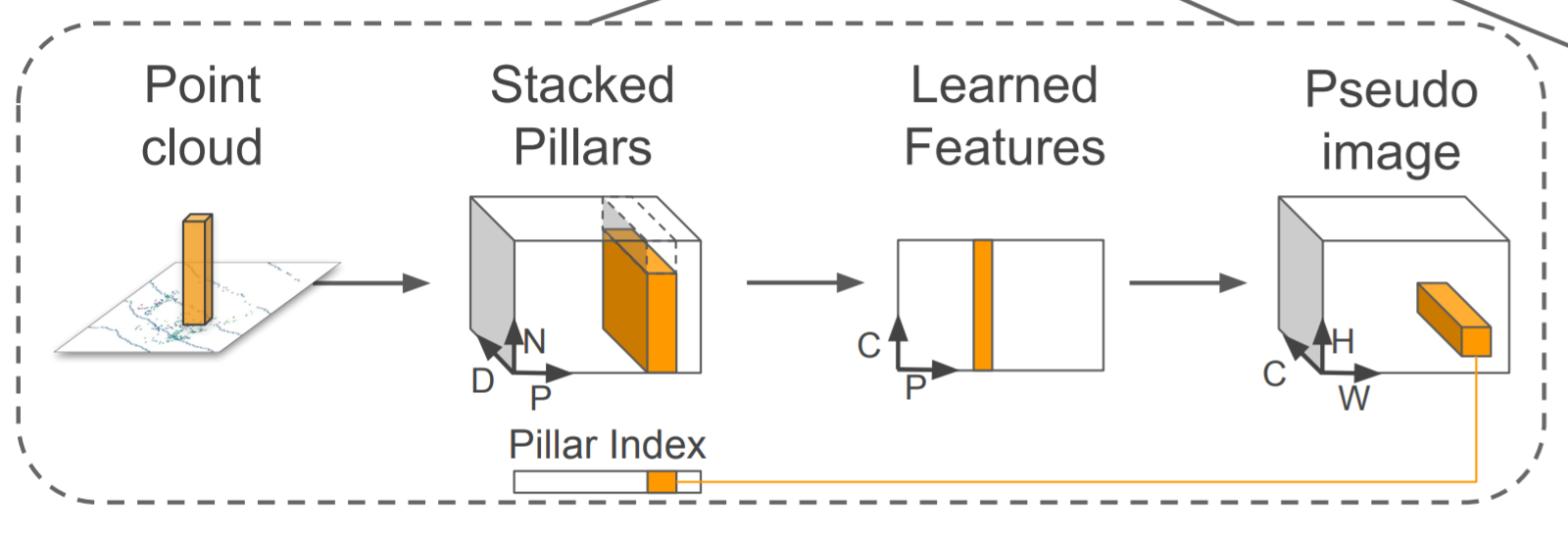 具体的に点群を画像にエンコードするために、Pillar(柱)と呼ぶ点群を細かく格子状に分割しPointNetのような点群DNNを使いPillar内の特徴量を抽出。そして得た2Dの特徴量マップをSSDに与えることで物体検出を行う。
アイデア自体は非常にシンプルながら、PointNetと物体検出CNNを結合する手法を初めて提案し点群物体検出の精度でブレイクスルーを果たした。
具体的に点群を画像にエンコードするために、Pillar(柱)と呼ぶ点群を細かく格子状に分割しPointNetのような点群DNNを使いPillar内の特徴量を抽出。そして得た2Dの特徴量マップをSSDに与えることで物体検出を行う。
アイデア自体は非常にシンプルながら、PointNetと物体検出CNNを結合する手法を初めて提案し点群物体検出の精度でブレイクスルーを果たした。
実験
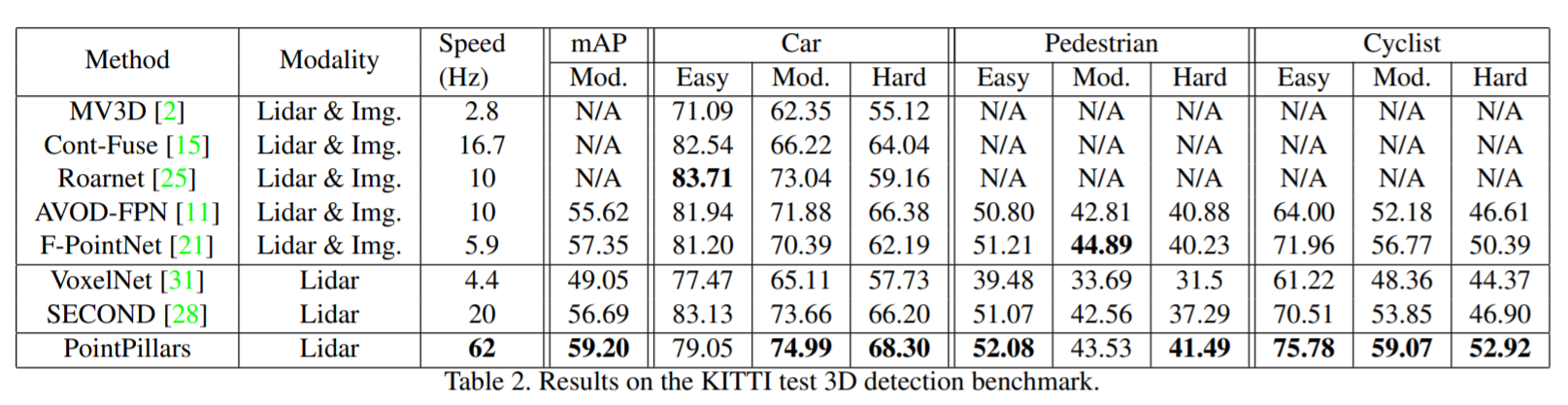 発表当時、KITTIベンチマークでstate of the artを達成。
発表当時、KITTIベンチマークでstate of the artを達成。
ネットワーク自身も改造しやすく、Kaggleなどのコンペでも頻繁に使われている。
https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles