Pytorch高速化 (2)Mixed Precision学習を試す
Qiitaからのお引越しです。
TLDR; (2021/06/17)
resnet50でCIFAR10をFP16により学習を2倍高速化でき、メモリ使用量も半分にできる。
pytorch1.6からデフォルトでMixed Precision学習をサポートしており、画像認識なら大抵これで上手く学習できます。 一部例外として、swin transformerだとapexを使用したほうが精度が良い場合もありました。
このチュートリアル通りにコードを書くのがおすすめです。 pytorch.org
use_amp = True # ampをオンオフ # Creates model and optimizer in default precision model = Net().cuda() optimizer = optim.SGD(model.parameters(), ...) # Create a GradScaler once at the beginning of training. scaler = torch.cuda.amp.GradScaler(enabled=use_amp) for epoch in epochs: for input, target in data: optimizer.zero_grad() # Runs the forward pass with autocasting. 自動的にレイヤ毎に最適なビット精度を選択してくれる(convはfp16, bnはfp32等) # ベストプラクティスを選択してくれるため、便利。use_amp=Falseではfp32を使用する。 with torch.cuda.amp.autocast(enabled=use_amp): output = net(input) loss = loss_fn(output, target) # Scales loss. # Scalerはautocasting以下では呼ばないこと。 # scaler.scale(loss).backward() scaler.step(optimizer) scaler.update() opt.zero_grad()
実際のcifar10学習コード:
目的
RTX2080tiを手に入れたのでPytorchにてFP16学習を試す。 Tensorcoreを使うことで演算速度がFP32に対する大幅な高速化が(スペック的に)期待できる。 どれくらい早くなるか、pytorchでどう書けばFP16が使えるかなど記述する。
BatchNormはFP32なので正確にはMixed-precision trainingだ。
codes: https://github.com/kentaroy47/pytorch-cifar10-fp16
そもそもFP16って?
FP16とは俗にいう”半精度”と呼ばれる浮動小数点における数字の表現方法である。 コンピュータの内部では数字は2進数で保存されており、例えば"3"という数字は:
0011 # 0*8+0*4+1*2+1*1 = 3
といった形で保存されている。これは一般的な4bitの整数表現(4bit Int)という形である。
ただこれでは0から15までの数字しか表現できない。
更に負や小数などを表現するのに使われるのが浮動小数点(float)と呼ばれる方式である。

上記の図(Googleより)は32bit浮動小数点(FP32)と16bit浮動小数点(FP16)の形式を示す。 これらはコンピュータの数字表現で最も一般的なフォーマットでFP32が単精度と呼ばれ、メモリを節約したい場合に使われるFP16が半精度と呼ばれる。
特徴として: ・MSB(最も左側のビット)が正負を決める ・Exponent 8bitは小数点位置を決める指数部である。 ・Mantissaは整数部を決める。上記のInt方式と同様である。
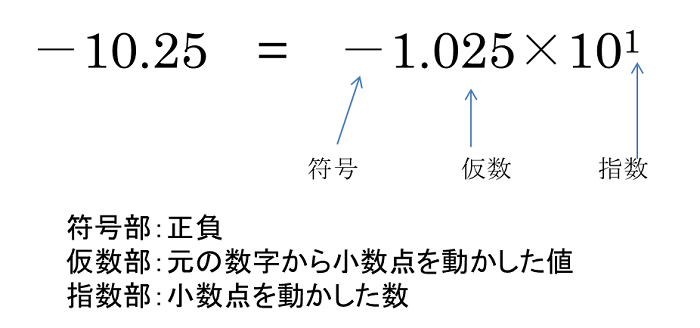 http://www.altima.jp/column/fpga_edison/bit_number_float.html
http://www.altima.jp/column/fpga_edison/bit_number_float.html
のように指数部をスケールすることで非常に幅広い範囲の数字を表現することができる。
FP16学習はDNNにどう関係するの?
1) メモリの節約 まずDNN学習時はGPUメモリ上にactivationやweightを保存し無くてはならない。 FP32方式でそれらのパラメータを保存するよりも、FP16で保存することで必要なメモリ量を半分にへらすことが出来る。
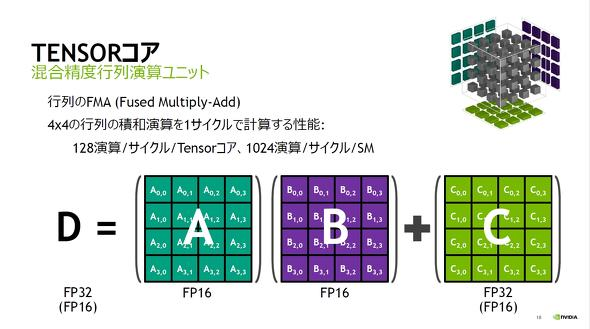 nVidiaより。
nVidiaより。
2) 演算の高速化 次世代GPUはFP16を使うと演算速度が大幅に向上するTensorCoreが搭載されている。 そのためFP16で学習することでFP32時に対し数十倍の演算速度向上が期待できる(スペック上は)!
環境
Ubuntu 16.04 Pytorch 1.0 CUDA 10.0 cudnn 7.4 GPU RTX2080ti
学習環境
FP16学習repo →https://github.com/kentaroy47/pytorch-cifar10-fp16 CIFAR10の学習repoを元に改造した。
python train_cifar10.py --fp16
でResnet18で学習開始。
FP16化にあたりポイント
https://github.com/fastai/imagenet-fast/tree/master/cifar10 Fast-aiのFP16化レポを参考に学習コードを改造した。
他の参考は: Training with Half Precision https://discuss.pytorch.org/t/training-with-half-precision/11815 https://pytorch.org/docs/stable/tensors.html https://devblogs.nvidia.com/apex-pytorch-easy-mixed-precision-training/
PytorchではFP16(half)がサポートされており、簡単にFP16化が可能。
FastAIのモデル16FP化コードを使わせていただいた。 https://github.com/fastai/imagenet-fast/blob/master/cifar10/fp16util.py のコードを使い、FP16化した。
何をやっているかというと、 入力、CNNのレイヤ→FP16化 BatchNormレイヤ→FP32化 している。
class tofp16(nn.Module): def __init__(self): super(tofp16, self).__init__() def forward(self, input): return input.half() def copy_in_params(net, params): net_params = list(net.parameters()) for i in range(len(params)): net_params[i].data.copy_(params[i].data) def set_grad(params, params_with_grad): for param, param_w_grad in zip(params, params_with_grad): if param.grad is None: param.grad = torch.nn.Parameter(param.data.new().resize_(*param.data.size())) param.grad.data.copy_(param_w_grad.grad.data) def BN_convert_float(module): # BatchNormのみFP32フォーマットにしないと性能が出ない。 # BatchNormレイヤを検索し、このレイヤのみFP32に設定。 ''' BatchNorm layers to have parameters in single precision. Find all layers and convert them back to float. This can't be done with built in .apply as that function will apply fn to all modules, parameters, and buffers. Thus we wouldn't be able to guard the float conversion based on the module type. ''' if isinstance(module, torch.nn.modules.batchnorm._BatchNorm): module.float() for child in module.children(): BN_convert_float(child) return module def network_to_half(network): return nn.Sequential(tofp16(), BN_convert_float(network.half()))
正直このfp16util.pyをコピーし、network_to_halfをネットワークに対し適応すれば良い。
net = ResNet18() from fp16util import network_to_half net = network_to_half(net)
学習速度
resnet18
batch = 128 FP32時:1 epochあたり15sec メモリ資料量:2000MB
FP16時:1 epochあたり10sec メモリ使用量:1500MB
50%高速化。 更にバッチ数、モデルサイズを大きくすると。。?
resnet50
batch = 512 FP32時:1 epochあたり57sec メモリ資料量:21000MB
FP16時:1 epochあたり27sec メモリ使用量:11727MB @TitanRTX
- メモリ使用量半分に
- 2倍高速化
両者とも50epochでval.89%ほどに到達。 精度的には更にチューニングが必要で(250 epochで93%くらいはいくはず)、FP16が精度的に問題ないかはまだわからない。
TODO: ちゃんと狙い通り16FPになっているかなど確認する。
CIFAR10より更に大きいデータセット
CIFAR10は画像サイズが小さく、演算よりもメモリ通信やデータローダがボトルネックになってしまっている?50%くらいしか早くなっていない。。
Resnet50ではちゃんと二倍高速化。メモリ半分はかなり嬉しい。
知り合いによるとImagenet学習ではほぼ2倍の速度向上が得られたとのこと。 そのうち試したい。
Nvidia Apex
https://devblogs.nvidia.com/apex-pytorch-easy-mixed-precision-training/
Nvidia謹製のpytorch FP16学習ツールが公開されました。
続編で試します