HAQ: Hardware-Aware Automated Quantization with Mixed Precision
HAQ: Hardware-Aware Automated Quantization with Mixed Precision (CVPR 2019 oral), Kuan Wang∗, Zhijian Liu∗,Yujun Lin∗, Ji Lin, and Song Han
課題
量子化はDNNをモバイルデバイスの高速化において重要な技術だが、各レイヤのビット幅などの設計は今まで手設計でルールベースなどで行われてきた。この論文ではレイヤ毎の量子化ビット数を自動的にハードウェアの性能を反映しつつ決定可能なHAQ技術を提案する。具体的には強化学習エージェントを使うことでレイテンシを最小化するパラメータを求める。
提案技術
mixed precision
DNNの量子化は幅広く使用されている技術であり、一般的には量子化はDNNの全レイヤを単一のビット幅になるよう圧縮を掛けてしまう。
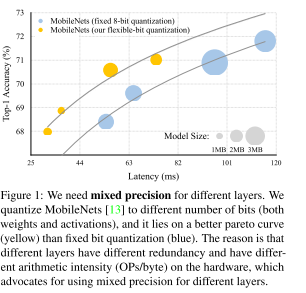
一方でDNNはレイヤごとに冗長性や演算密度が異なり、レイヤ毎に量子化ビット数を最適化した方が性能向上が狙えるというのが発想(Fig.1)。 このようなflexible-bit qunatizationによって性能・レイテンシトレードオフを改善するというのが研究の狙い。
ハードウェア-awareな性能見積もり
 FLOPS等の指標はモデルの計算量を簡単に机上で見積もることができるため、幅広く使われている。一方でFLOPSはモバイルデバイスのレイテンシに直結しておらず、有用な指標でないことを指摘。実際はハードウェアのキャッシュサイズやメモリバンド幅などが支配的になるのでFLOPSは当てにならないことが多い。(ビットシフトは0FLOPSなので演算量はなしとした狂った論文もありましたね。。)
FLOPS等の指標はモデルの計算量を簡単に机上で見積もることができるため、幅広く使われている。一方でFLOPSはモバイルデバイスのレイテンシに直結しておらず、有用な指標でないことを指摘。実際はハードウェアのキャッシュサイズやメモリバンド幅などが支配的になるのでFLOPSは当てにならないことが多い。(ビットシフトは0FLOPSなので演算量はなしとした狂った論文もありましたね。。)
そこでHAQではRLエージェントのアクション中にハードウェアを直接盛り込むことでハードウェアレイテンシを直接観測する(Fig.2)。力技だが、HW性能見積もりをちゃんとやっているのでHardware-awareな見積もりが可能。HWは実際にはFPGAにて実装している模様。
RL agent
RLエージェント報酬はレイテンシではなく、量子化後の精度としている

リソース最小化はRLエージェントではなく、アクションスペースの制限で達成している。 簡単にいってしまうとRLエージェントが提案する量子化ビット数候補に対しリソース(レイテンシ、モデルサイズ)を計算し、もしそれが要求を満たしていなかったら各レイヤのビット幅をリソース制限を満たすまで少しずつ減らしていく。そのためRLで直接量子化ビット幅自体を最適化しているわけではない。 直感的にはターゲット精度を達成するための最適な量子化ビット数を探索するようなアルゴリズムに見える。そのためリソース制限を厳しくすることで、そのリソースで得られるベストな量子化組み合わせを探索するイメージ。
手法はかなりローテクな気がするが、リソースをRLエージェントの報酬にするよりは探索空間が狭くて上手くいくということか。
離散化アクションスペースでは量子化ビット数の大小の関係を組み込むことができないため、α=[0,1]の連続値を入力し離散ビットを出力する関数を用いて擬似的に連続的なアクションスペースを作成する。

結果
 決め打ち量子化(PACT)に対しHAQは同等のレイテンシで高精度達成。
決め打ち量子化(PACT)に対しHAQは同等のレイテンシで高精度達成。
 面白いことにモバイルデバイス向けではdepthwise convolutionのビット幅を縮小するようにしている。おそらくモバイルデバイスではdepthwise convでメモリ律速になりやすく、その点を解消しようとRLエージェントが最適化をかけていると考察。
面白いことにモバイルデバイス向けではdepthwise convolutionのビット幅を縮小するようにしている。おそらくモバイルデバイスではdepthwise convでメモリ律速になりやすく、その点を解消しようとRLエージェントが最適化をかけていると考察。