TensorRT-LLMとは
TensorRTをLLM用に多数の推論高速化技術を入れたNvidiaのオープンソースフレームワーク。
GPUメモリ使用率を半分に低減し、速度も1.5-2倍程度改善してくれる強力なフレームワーク。
TensorRT-LLMについてはこちらのAlibaba解説がわかりやすい。
特徴
量子化による省GPUメモリ
重み、Activation量子化を積極的に入れ込み、GPUメモリ使用量を半分以下に削減。
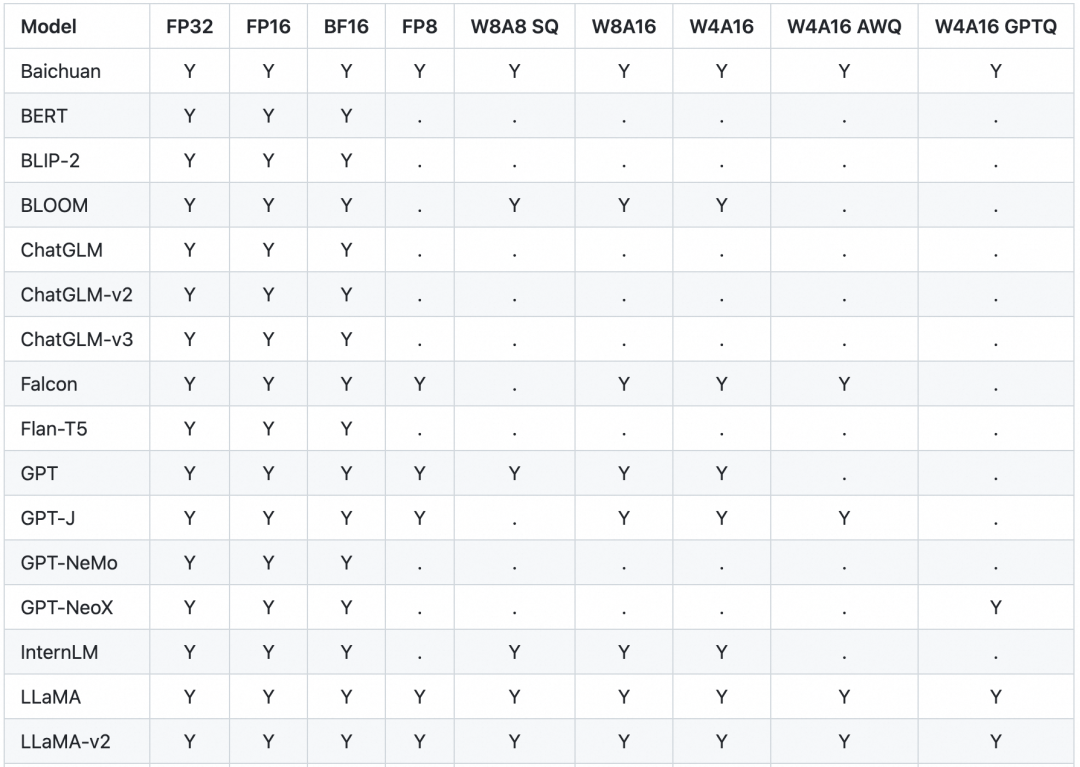
W8A8 SQ uses the SmoothQuant technique[2], which reduces the model weight and activation layer to the quantization precision of INT8 without reducing the accuracy of model inference, significantly reducing GPU memory consumption.
W4A16 or W8A16 means that the model weight is at the quantization precision of INT4 or INT8, and the activation layer is at the quantization precision of FP16.
INT8,INT4を使用する事ができるらしい。こちらの量子化を活用しつつ精度を出すには量子化および演算時にレンジ調整などが必要だが、TensorRT側でハンドリングしてくれるのがありがたい。
In-flight Batching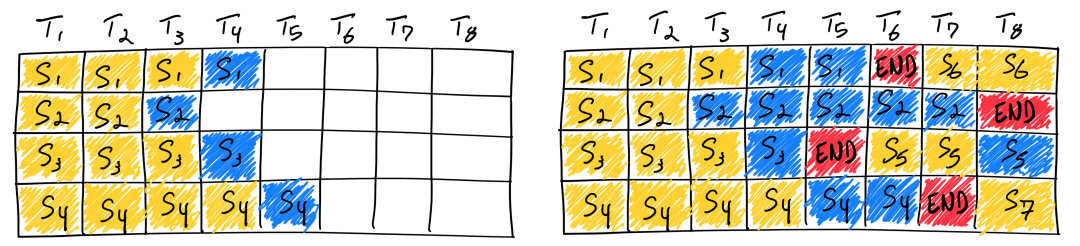
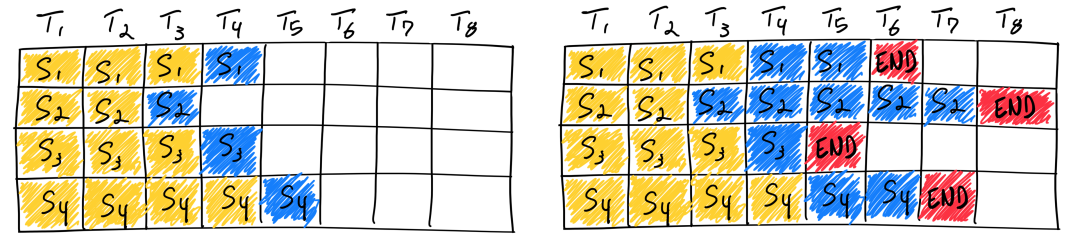
LLM推論サービスに重要な機能。
効率的な推論には大きなBatchで動作させることが欠かせないが、LLMではBatch毎に動作するシーケンス長が異なってしまう。そのため全てのBatchが動作完了するまで待っているとGPUを有効に活用することができない。
そこでIn-flight batchingでは計算終了したBatchに次のBatchを与える。これによってGPU使用率を常に高く維持することができ、時間当たりのLLM処理トークン数を最大化できる重要な技術となる。
こちらの論文で提案された技術?
モデルコンパイル
TensorRTと同様にモデルをコンパイルすることで推論高速化。
参考:
例えばMLPレイヤとNormalizeレイヤを一つのレイヤにまとめるレイヤフュージョンなどの技術によってメモリ読み書きの回数を減らし高速化を達成する。
- LLMに向けた推論技術
LLM推論に向いた多くの推論技術をまとめてくれる。
例えばKV cacheといった技術は最初のpromptを計算する際のattentionのcacheを保存し、以降の計算時に再利用する。
TensorRT-LLMを動かす
こちらの導入を参考にMistral 7B Instruct v0.2を動かしてみる。
導入
Python=3.10.12で環境作成。
trtllmはUbuntu > 20でないと対応していないので、ない場合はdockerを使う。
docker run --rm -it --entrypoint bash nvidia/cuda:12.2.2-devel-ubuntu22.04
git clone https://github.com/NVIDIA/TensorRT-LLM.git cd TensorRT-LLM/examples/llama pip install mpi4py # ないと下でコケる pip install tensorrt_llm -U --pre --extra-index-url https://pypi.nvidia.com
# モデルをダウンロード
from huggingface_hub import snapshot_download
snapshot_download(
"mistralai/Mistral-7B-Instruct-v0.2",
local_dir="tmp/hf_models/mistral-7b-instruct-v0.2",
max_workers=4
)
次にモデルをtensorrt-llmでコンパイルする。
こちらは1分ほどで完了する。
python convert_checkpoint.py --model_dir tmp/hf_models \
--output_dir tmp/trt_engines \
--dtype float16
そして最後にrun。
cd ..
python run.py --max_output_len=256 \
--tokenizer_dir ./llama/tmp/hf_models/mistral-7b-instruct-v0.2/ \
--engine_dir=./llama/tmp/trt_engines/compiled-model \
--max_attention_window_size=4096
推論速度比較
TBD