Pytorch高速化 (1)Multi-GPU学習を試す
Qiitaからのお引越しです。
Pytorch Advent Calender 2018 3日目の記事です。
はじめに
学生に"Pytorchのmulti-GPUはめっちゃ簡単に出来るから試してみ"と言われて重い腰を上げた。
複数GPU環境はあったのだが、これまでsingle GPUしか学習時に使ってこなかった。 試しに2x GPUでCIFAR10を学習しどれくらい速度向上が得られるか実験。 またpitfallなどあったら報告する。
環境
GPU: TitanXp *4 OS: Ubuntu 16.04 Pytorch: 0.4.0 Python: 3.5 Network: Resnet 18
codes:
GitHub - kentaroy47/pytorch-mgpu-cifar10: testing multi gpu for pytorch
GPUコマンドあれこれについて:
MultiGPUにするには。。
Code的には超単純. モデルにtorch.nn.DataParallelを適応するだけでmultiGPUが使用可能となってしまう。。恐るべし。
Pytorchマニュアル。
device = 'cuda' if torch.cuda.is_available() else 'cpu' # ネットワーク宣言 net = ResNet18() # cuda or cpu? net = net.to(device) # 複数GPU使用宣言 if device == 'cuda': net = torch.nn.DataParallel(net) # make parallel torch.backends.cudnn.benchmark = True
torch.nn.DistributedDataParallelを使用すると1GPUに対し1CPUを割り当てるためより早くなるのですが、学習ループの書き方が変わるのが注意です。
リンクを参照してみてください。
single GPUで学習.
まずはシングルGPUで学習する。 使用GPU切り替えはターミナルにて
export CUDA_VISIBLE_DEVICES=0 python train_cifar10.py --net res18
とGPUが一つしか見えないように宣言すれば良い。

1epochあたり21秒かかっている。
multi GPUで学習
ここでは2つのGPUを使って学習してみる。 どれくらい早くなるかな?理想的には2倍だがCIFAR10は小さいのでどうか。
シェルでGPUが2つ見えるように切り替えておく。
export CUDA_VISIBLE_DEVICES=2,3 python train_cifar10.py --net res18
 学習を開始し、正常に同じIDのプロセスがGPU2,3に入っている事を確認。
学習を開始し、正常に同じIDのプロセスがGPU2,3に入っている事を確認。
あれ?
 1 epochあたり15秒。
40%ほどしか高速化していなくておかしい。。
1 epochあたり15秒。
40%ほどしか高速化していなくておかしい。。
batch数を増加させる。
https://pytorch.org/tutorials/beginner/former_torchies/parallelism_tutorial.html
One can wrap a Module in DataParallel and it will be parallelized over multiple GPUs in the batch dimension.
チュートリアルによるとBatchレベルで並列化しているよとある。 Batchが2個あったら一つをGPU1,もうひとつをGPU2に渡しているということだ。
このスクリプトだとBatch数=128でDataloadしているが、GPU1にBatch=64 GPU2にBatch=64が渡されることになりSingle GPU時に比べBatch数が少なくなっている。
つまりGPUを2つ使う場合はDataloaderのBatch数も2倍にしなければならない。
trainloader = torch.utils.data.DataLoader(trainset, batch_size=256, shuffle=True, num_workers=8)
dataloaderのバッチ数を2倍の256に設定。

すると1 epochあたり13秒に改善。 2GPU化により60%早くなったのでまあまあかな。データセットが小さいのがまだ足をひっぱている気がする。まだ遅い。
Batch=378まで大きくしてみたがあまり変わらず。
Resnet50 + 101で実験
ネットワークを大きくしてみれば恩恵が大きくなるかと思い実験。 Res50では速度改善は77%!理想に近づいてきた。 ImageNetサイズまでスケールアップすると更に良くなりそう。
ネットワークサイズが小さいとマルチGPUにより計算時間はスケールできる。がgradientをreduce,computeする部分はシリアルのためボトルネックとなってしまう。
| Res18 | Res50 | Res101 | |
|---|---|---|---|
| SingleGPU | 21s | 72s | 126s |
| MultiGPU(*2) | 13s | 44s | 77s |
| Improvement | 60% | 77% | 63% |
Res101では学習速度の向上は50ほど良くない。 速度コンペでRes50を皆使うのは一番速度がいい感じで出るからなのだろうか(笑)
singleGPUとMultiGPUのロスを比較
普通バッチ数を2倍にすると学習係数を2倍にしないと学習結果が変わってしまう。
MultiGPU時はどう考えればいいんだっけ? →ざっと検索してもわからなかったので試してみた。
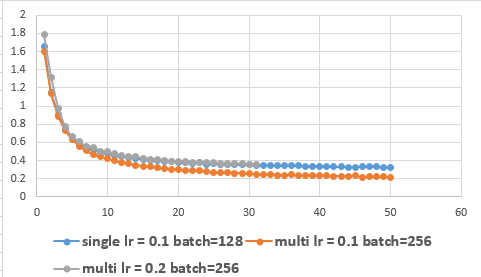
single lr=0.1, batch=128と等価なのはmulti(2GPU) lr=0.2, batch=256であった。multi(2GPU) lr=0.1, batch=256は学習の進みが異なる。
マルチGPUのデータの流れはどうなってる?
演算としてはBatch[0:255]のデータを
GPU1 Batch[0:127] GPU2 Batch[128:255]
のようにアサインする。するとbackpropによりバッチ数分のgradientが生成される。
GPU1 grad[0:127] GPU2 grad[128:255]
となり、これらは集約する必要がある。
# parameter update Weights += -sum(grad[0:255]) * learnrate
のような演算を行うため、パラメータアップデート時には何個のGPUに分散したかどうかは関係ない。
結論 (or main takeaways)
1. PytorchでmultiGPUを使う際はBatchsizeも使用するGPU数に比例させ増加させなければ十分な学習速度向上は得られない。
2. Batch数を増やしたらその分学習係数も増やさなければ学習結果は変わってしまう。またはパラメータアップデート時に何個のGPUに分散したかどうかは関係ない。
3. ネットワークサイズはある程度ないとマルチGPUの恩恵は受けられない
gradientをbatch要素毎に計算→CPUに戻しbackprop時に学習率を適応するのでGPU数を増やしても学習率に影響はないと予想..
さらなる高速化のために
TensorRTで推論高速化 aru47.hatenablog.com