またまたQiitaからのお引越し記事です。
センサについてはこちらをどうぞ。
目的

点群データに対してディープニューラルネットワーク(DNN)を適応する研究は活発で、いくつものアプローチがあります。 大人気のPointNetだけではなく、他の手法も照らし合わせて各手法のメリット・デメリットを理解する自助をすることが記事の目的です。
浅く広く手法について学び、ああこういうアプローチがあるのかと気づくことができると幸いです。 各技術の詳細を知りたい場合は元論文や解説サイトを読むといいと思います。
またPointCloud DNNの論文についてはここにわかりやすくまとまっています。是非一読を!
点群DNNでできること
- 点群認識

与えられた点群が何の物体か認識するタスクです。 例えばShapenetにおいては点群がどの家具か当てるタスクがあります。 画像認識と同様のタスクです。
- 点群セグメンテーション

SUN-RGBDにあるタスクです。 点群がどの物体に属しているかセグメンテーションするタスクです。 画像セグメンテーションと同様のタスクです。
- 点群物体検出
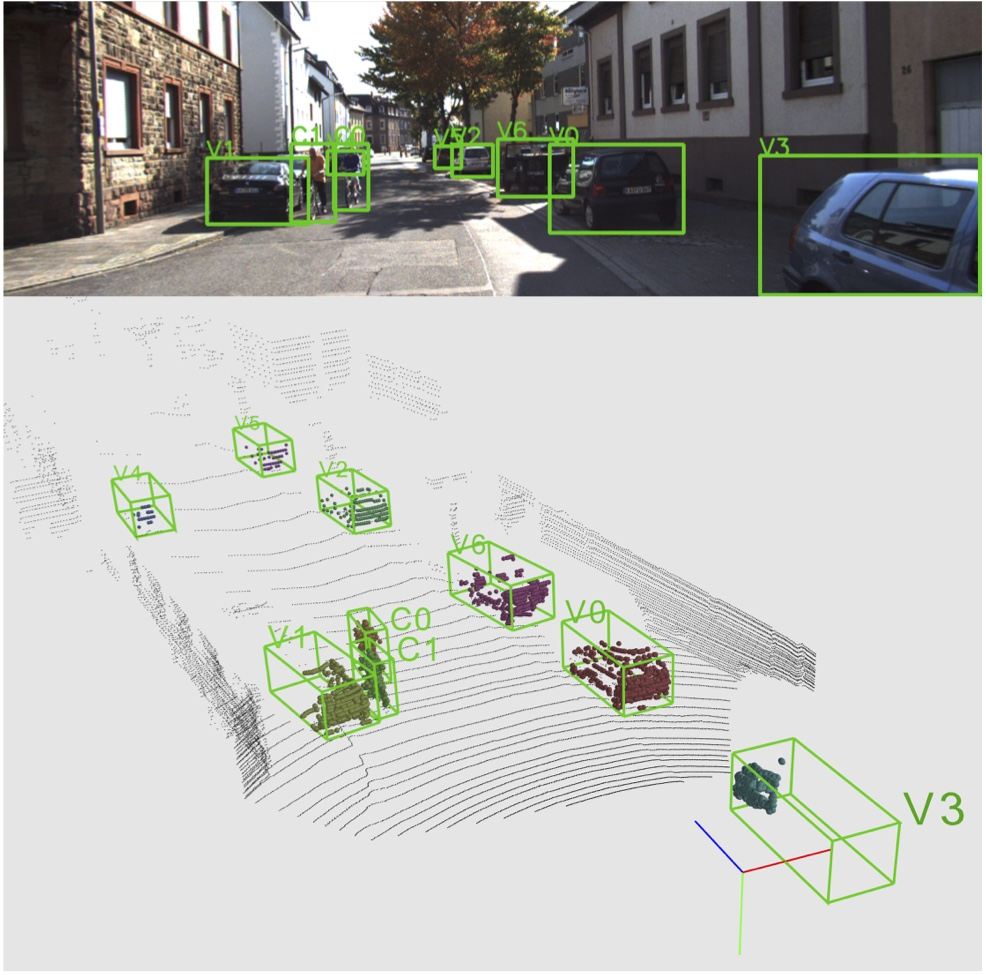 自動運転などに重要な点群中に存在する物体の座標を認識するタスクです。
アプリ的に需要が高く、一番研究としては人気のあるタスクな印象です。
自動運転などに重要な点群中に存在する物体の座標を認識するタスクです。
アプリ的に需要が高く、一番研究としては人気のあるタスクな印象です。
3Dセンサ
RealsenseD435はアマゾンで24000円と手頃でAPIも使いやすいです。
点群を取得してみたいのならば試しに買ってみてはいかがでしょうか。
3D DNNの家計図
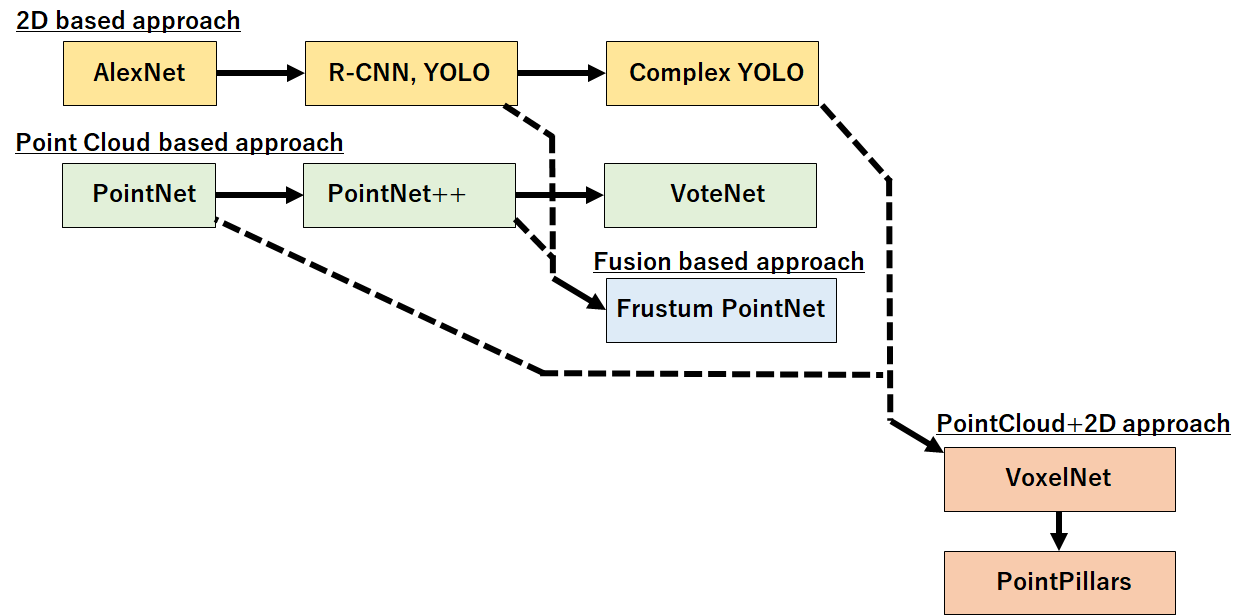
独断と偏見で3D DNN系の家系図を作ってみました。
大きくは * 2Dベースのアプローチを結集する2D based * あくまで点群にニューラルネットワークを適応するPoint cloud based approach * 画像から得た結果と点群ニューラルネットワークをフュージョンするアプローチ * また点群ニューラルネットワークで点群を前処理(エンコード)した後に2Dベースの物体検出を適応するPointCloud+2D アプローチ の四種類があると考えています。
それぞれを詳しく見てみましょう。
変更履歴
使うデータドメイン毎にカテゴライズを変更(2019/10/2) データセットなど加筆(2019/10/2) Pointpillars追加(2020/03)
2Dベースアプローチ
Complex YOLO (ECCV workshop 2018), YOLO 3D (ECCV workshop 2018)
Complex-YOLO: An Euler-Region-Proposal for Real-Time 3D Object Detection on Point Clouds
https://link.springer.com/chapter/10.1007/978-3-030-11009-3_11
YOLO 3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud
手法について
タスク:自動運転用の三次元物体検出 LiDARの点群はデータ量が少なく(疎)であるため、点群から物体の情報を直接抽出するのは難しい。
そこで点群を俯瞰的視点(上からみた)の画像を生成し、それに対し物体検出の手法(YOLOやFaster-RCNN)を適応するという手法です。 点群データも俯瞰視点に変換してしまえば車や人なども画像のように扱うことができます。 そのため成功をすでに収め、人間レベルの検出が可能なCNNを積極的に3Dの分野でも適応しようというのがベースの考え方です。
俯瞰(bird's eye viewまたはBEV)とは?
 上の図が正面からみたカメラで下の図が俯瞰視点でみた点群です。
これを画像として扱い、物体検出DNNを適応します。
上の図が正面からみたカメラで下の図が俯瞰視点でみた点群です。
これを画像として扱い、物体検出DNNを適応します。
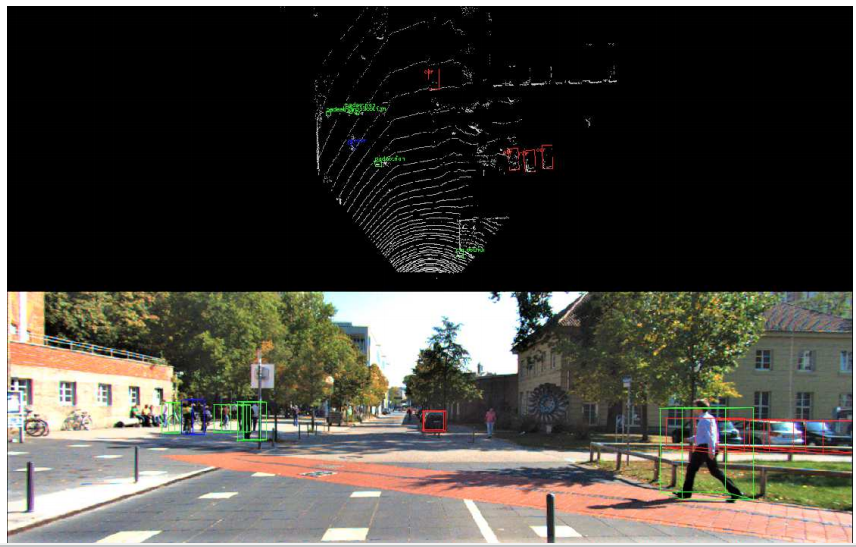
メリット
2D画像で成功したディープなR-CNNベースの手法をそのまま点群データに対し適応することができる。
R-CNNはImageNetやMS-COCOなどから転移学習できるので、必要な学習データ量が少なく済む可能性がある。
YOLOベースのため高速。リアルタイム動作も可能。
デメリット
点群を二次元化してしまうので物体の三次元的特徴(凸凹など)は読み取れない。
多角的に検出を行うことは可能だが、角度間(例えば俯瞰と正面)の検出結果の整合性を取るのが難しく検出を間違えたりしてしまう。
(あと3D研究者からすると手法がストレート過ぎておもしろくない笑)
点群ベースアプローチ (PointNet系)
PointNet(NIPS 2016)
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
https://arxiv.org/abs/1612.00593
みんな大好きPointNet。
https://www.slideshare.net/FujimotoKeisuke/point-net
https://qiita.com/KYoshiyama/items/802506ec397559725a1c
に詳しい解説があるのでそちらも読むことをおすすめします。
PointNetの手法について

点に対し全結合ネットワークを複数回かけ合わせ、特徴量を抽出していく(Classification Network)。
そして最終的に得られた点に対する特徴量(n*1024部)をmaxpoolingすることで点群全体の特徴量(global feature)を得る。
点に対する特徴量抽出後、maxpoolingで全体特徴量を得ることが出来ることを示したのがPointNet最大の功績じゃないかと考えている。これでいいんだ!!という感じ。。笑

点群に対するクラス分類、セグメンテーション両方に対して(ModelNet,SUNRGB-D)非常に高いスコアを叩き出した。
PointNetのタスク
PointNetが効果を発揮するのはデータセットは主に室内で取られた点群データに対してです。

報告されているのは室内のセグメンテーションを行うSUNRGB-Dデータセット(上図)
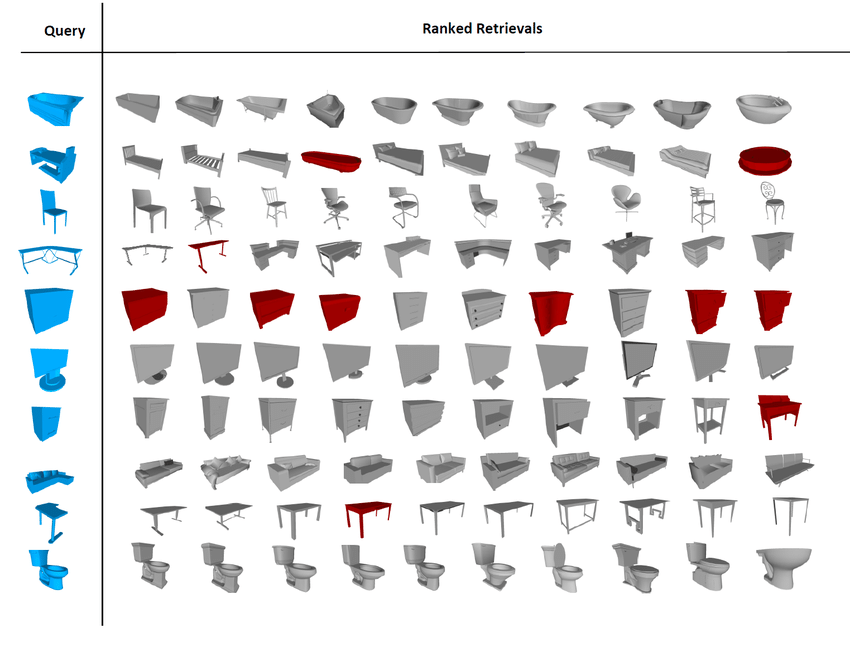
そして家具単体のクラスを当てるModelNet40です。
自動運転のようなKittiデータセットに対しては点群が疎すぎるため、適応できないとのこと。 これは後に2Dと3DをフュージョンするFrustrum PointNetで解決されました。
PointNetの実装
PointNet-Tensorflow(本家) https://github.com/charlesq34/pointnet
PointNet.Pytorch(自分もこれを使っており、本家同等の精度が出るのを確認してます) https://github.com/fxia22/pointnet.pytorch
PointNet-Keras https://github.com/garyli1019/pointnet-keras
PointNet-Chainer https://github.com/corochann/chainer-pointnet
PointNet++(NIPS 2017)
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space https://arxiv.org/abs/1706.02413
PointNetの局所的特徴を見ていない(近傍点群の情報を取り込めない)、という課題を改良したPointNet++も人気と実力が高いです。
PointNetに入力する点群を事前にクラスタリングした近傍点を入力することで、擬似的に局所的特徴量も抽出できるようになっています(後日加筆します。。)
まずはとっつき始めるならばPointNet,研究を行うならばPointNet++を元に実装を行うべきと思います。
実装
PointNet++.pytorch https://github.com/erikwijmans/Pointnet2_PyTorch
VoteNet(ICCV 2019)
Deep Hough Voting for 3D Object Detection in Point Clouds http://arxiv.org/abs/1904.09664
PointNet生みの親からの室内のオブジェクトの3D物体検出に向けた最新論文。 現在ScanNetv2ベンチマークにおいてSoTA。
点群の物体検出タスクは複雑な実装が多く、精度もあまり出ていなかった。 一方VoteNetはシンプルなアイデアながら、高い精度を実現。 基本的なアイデアは物体の中央をhough-votingで予測し、予測した中心点を元に物体検出するというもの(後日加筆します)。
今後人気が出てくるようと思うので要ウォッチ。
センサフュージョンベースアプローチ
Frustrum PointNets
Frustum PointNets for 3D Object Detection from RGB-D Data
https://arxiv.org/abs/1711.08488
手法について
PointNetでは物体検出のタスクにはあまり向かない。
そこでカメラとLiDARデータのセンサフュージョンを行い、精度向上を達成。
そこで成功を収めている2DベースR-CNNで物体のある方向を円錐で絞り込んでから、その部分の点群のみPointNetにかけることで高精度な3D物体検出を実現。
これもアイデアは非常に単純だが、効果絶大なアプローチである。自動運転用など高い精度が求められる三次元物体検出を行うならばこのアプローチが一番スタンダードなのではないだろうか。
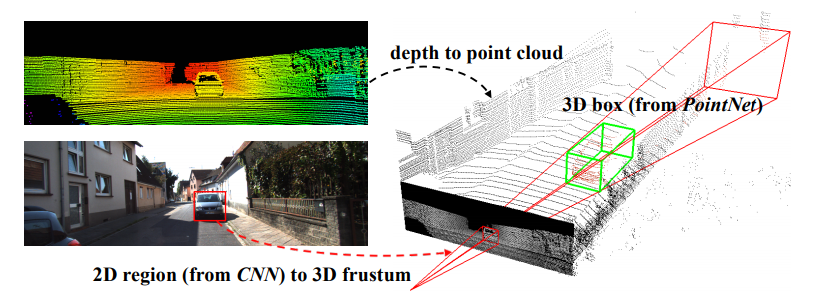
3D bindingbox predictionを行うPointNetも新規に提案している。

メリット
カメラ+LiDARを用いた3次元物体検出のタスクにおいてstate-of-the-art。(Kittiデータセット)
有力な2つの手法を組み合わせているので実装がしやすい。
デメリット
モデルを縦続的に使うので演算量は多い。
そもそもカメラで取り逃した物体は検出できない。
実装
https://github.com/charlesq34/frustum-pointnets
点群+2D CNNのアプローチ
VoxelNet(CVPR 2018)
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
手法について
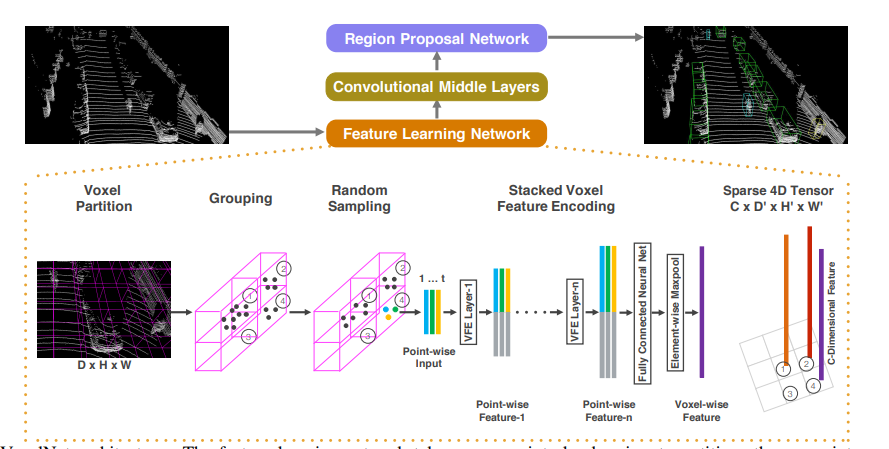 この論文のポイントは点群にPointNet-likeなネットワークで特徴抽出を行った後に、2Dベースのアプローチ(Region CNN)を適応することで物体検出を行います。2D CNNに直接点群を入力すると点群の精微な情報を読み取れないという弱点を最初にPointNetで特徴抽出を行うことで解決したのが進歩性です。
この論文のポイントは点群にPointNet-likeなネットワークで特徴抽出を行った後に、2Dベースのアプローチ(Region CNN)を適応することで物体検出を行います。2D CNNに直接点群を入力すると点群の精微な情報を読み取れないという弱点を最初にPointNetで特徴抽出を行うことで解決したのが進歩性です。
また物体検出自体はCNN系手法の方が精度が高いため、PointNetとR-CNN両方の長所を使っているという意味で興味深い手法です。
Voxelとは?
 左の絵が生の点群データです。
点群データはポイント数が多く扱いにくいので、複数を一纏まりにしたVoxelに変換します。Voxelは粒度によっては点群のように振る舞いますが、荒くすると昔のゲームのポリゴンくらいになってしまいます。
ざっくばらんに言うとはダウンサンプルした点群と捉えることができます。
左の絵が生の点群データです。
点群データはポイント数が多く扱いにくいので、複数を一纏まりにしたVoxelに変換します。Voxelは粒度によっては点群のように振る舞いますが、荒くすると昔のゲームのポリゴンくらいになってしまいます。
ざっくばらんに言うとはダウンサンプルした点群と捉えることができます。
空間的情報を保ったままデータ量、演算量を削減できるため、3D DNNが流行る前から点群の位置合わせ(レジストレーション)を行う際にはボクセル化は定番のアプローチです。
メリット
Voxel間で畳み込みを行うため、後述するPointNetではできない近隣点群間の特徴量も抽出することが可能です。
Voxelの特徴量の他にPoint自体の特徴量抽出も行っているため(直感的には)情報のロスはなく、高精度な認識が期待できます。
PointNetとCNNの良いところどりをしたようなアーキテクチャ。
デメリット
メモリ使用量が多い。
ランダムサンプルやVoxel間隔をチューニングすれば軽くすることは可能だが、チューニングが大変。
公式実装がリリースされていない。
ここに公式では有りませんが実装がありました。
PointPillars: Fast Encoders for Object Detection from Point Clouds
CVPR 2019. https://arxiv.org/abs/1812.05784
- 課題

従来点群のみ使用したネットワークは精度は高いが低速で、点群を画像に投影するネットワークは高速だが 精度が低いという欠点があった。
- 提案
 狙いとしては点群の細かい情報量を失わないように情報量をエンコードし、疑似画像に変換する。その疑似画像を2D CNNで使用するような物体検出ネットワークに入力し、物体検出を行う。
この手法の進歩性は従来単純に点群を俯瞰画像といった疑似画像に投影し物体検出CNNに入力するだけでは点群の細かい情報量が失われてしまっていた。そこで点群を画像に投影するためのエンコードネットワークを用いることで点群情報を失わずに物体検出CNN(SSD)に入力データを与え高精度化を達成した。
狙いとしては点群の細かい情報量を失わないように情報量をエンコードし、疑似画像に変換する。その疑似画像を2D CNNで使用するような物体検出ネットワークに入力し、物体検出を行う。
この手法の進歩性は従来単純に点群を俯瞰画像といった疑似画像に投影し物体検出CNNに入力するだけでは点群の細かい情報量が失われてしまっていた。そこで点群を画像に投影するためのエンコードネットワークを用いることで点群情報を失わずに物体検出CNN(SSD)に入力データを与え高精度化を達成した。
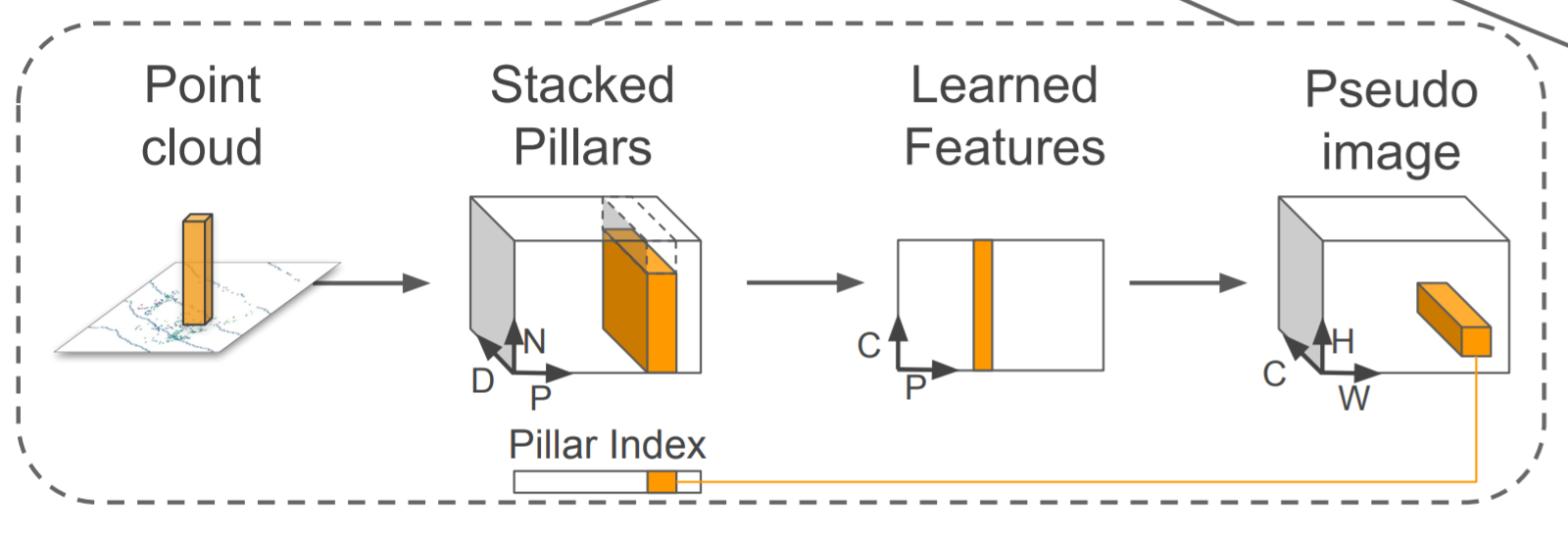 具体的に点群を画像にエンコードするために、Pillar(柱)と呼ぶ点群を細かく格子状に分割しPointNetのような点群DNNを使いPillar内の特徴量を抽出。そして得た2Dの特徴量マップをSSDに与えることで物体検出を行う。
アイデア自体は非常にシンプルながら、PointNetと物体検出CNNを結合する手法を初めて提案し点群物体検出の精度でブレイクスルーを果たした。
具体的に点群を画像にエンコードするために、Pillar(柱)と呼ぶ点群を細かく格子状に分割しPointNetのような点群DNNを使いPillar内の特徴量を抽出。そして得た2Dの特徴量マップをSSDに与えることで物体検出を行う。
アイデア自体は非常にシンプルながら、PointNetと物体検出CNNを結合する手法を初めて提案し点群物体検出の精度でブレイクスルーを果たした。
- 実験
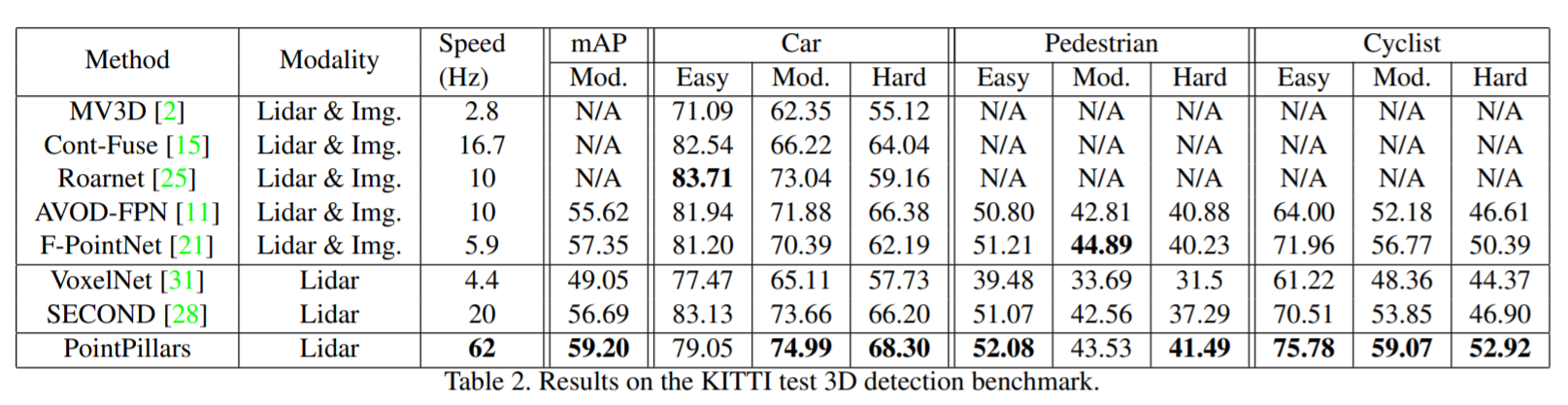 発表当時、KITTIベンチマークでstate of the artを達成。
発表当時、KITTIベンチマークでstate of the artを達成。
ネットワーク自身も改造しやすく、Kaggleなどのコンペでも頻繁に使われている。
https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles
Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection
https://arxiv.org/pdf/1908.09492.pdf
現在のNuscenes一位のソリューション。

課題 LiDARデータのaugumentationの提案が主に精度向上の要因。 Nuscenesはクラス間精度の平均が評価指標になっているが、学習データ数がクラスによっては異常に少なく学習が進まない。例えば最も頻出する車クラスに対して人やanimalクラスは1/10から1/100しかない。

提案 このようなデータセットインバランスに対応するため、点群データ中に少数クラスを恣意的に生成することで学習を進みやすくした。ネットワーク自体はほぼPointpillarsの応用で、データセット拡張により大幅な精度向上を実現した。また精度に貢献している提案として大きさなどが似ているクラス(人と自転車など)を"superclass"としてまず分類してから詳細クラスを分類する2-stepの分類を実行している。
 特に自転車クラスは14倍も精度向上した。
特に自転車クラスは14倍も精度向上した。
点群系(3D)のベンチマーク
ModelNet40
一番基本的な3D系のベンチマーク。
90%精度が出てしまっているので、モデルがオーバーフィット気味でベンチマークの価値は現在あまりなくなった。MNIST的に学習時間も短いので最初に試すのはこれ。
https://paperswithcode.com/task/3d-object-classification
現在は3D capsulenetがリーダー。

ScanNetv2
現在の室内用3Dデータでは一番難しいタスク。 VoteNetが一位ですね。 https://paperswithcode.com/sota/3d-object-detection-on-scannetv2

自動運転系
nuScenes
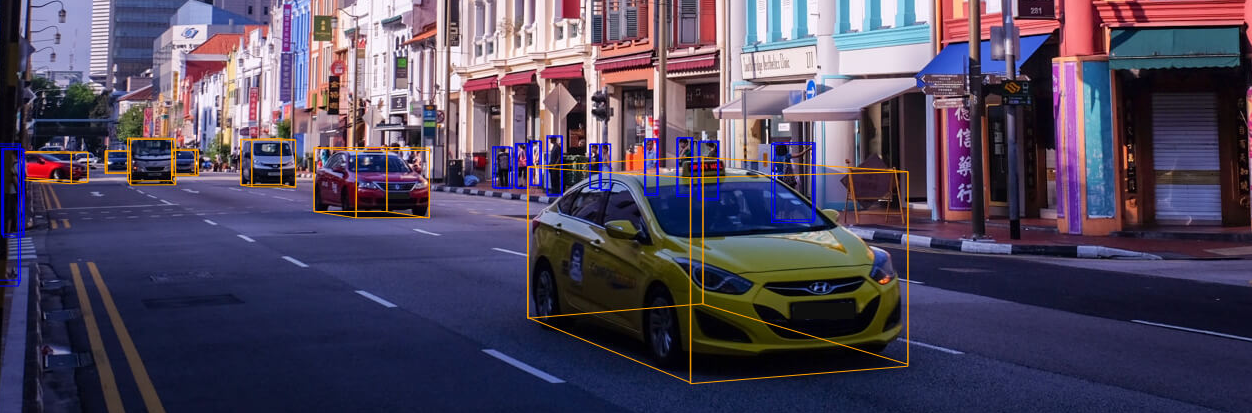 現在では最も難しく、巨大なデータセット。
現在では最も難しく、巨大なデータセット。
- 大規模点群+カメラ画像のアノテーション結果
- 20秒で区切られた1000シーンのデータ
- ボストンとシンガポールの街中
- 23クラスの結果
https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any
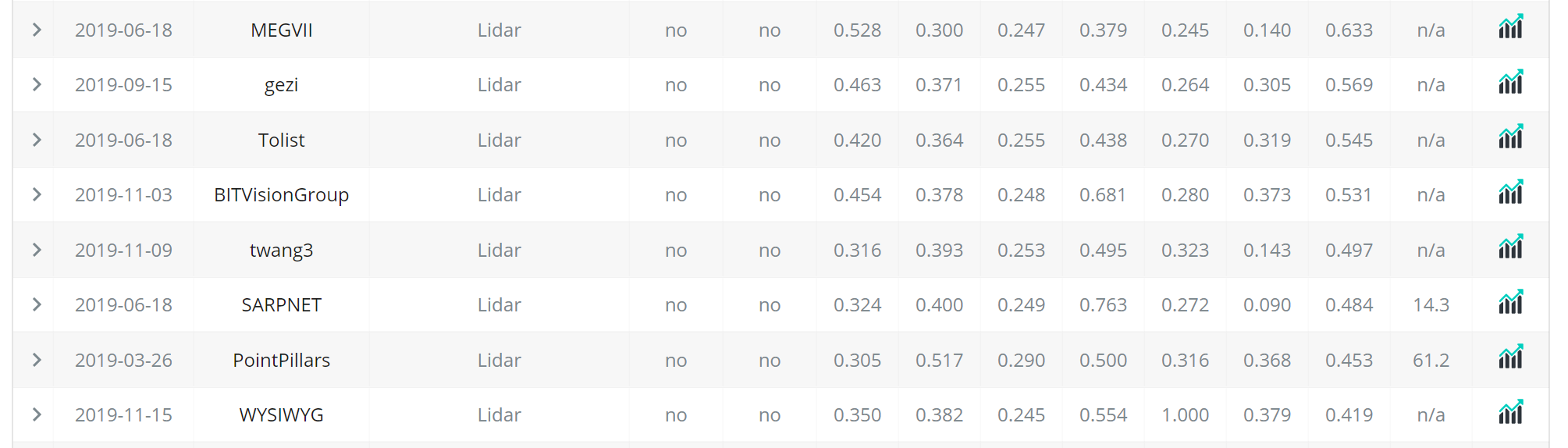 ベンチマーク首位はMEGVIIでPointpillarsは結構精度は低い。
一方でPointpillarsは使いやすく、KaggleのLyftコンペではほとんどの上位陣が使った。
https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles
ベンチマーク首位はMEGVIIでPointpillarsは結構精度は低い。
一方でPointpillarsは使いやすく、KaggleのLyftコンペではほとんどの上位陣が使った。
https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles
KITTI

従来まで使われていたデータセット。 データ数はあまり多くないが、データセット形式が使いやすくスタートするには最適。 http://www.cvlibs.net/datasets/kitti/
PS
逐次最新論文等は自分のブログにまとめてます。