https://www.kaggle.com/kyoshioka47
目的
この度約10ヶ月間Kaggleに参戦しCompetition Masterになり賞金も獲得できました。本記事では参戦したコンペ中の思考や得られた事を振り返り記録します。これからKaggleを始めMasterを目指す人の参考になればと思います。
また試しに昔登録したamazonアフィリエイトのリンクをいくつか貼ってみました。コーヒー代を寄贈する気持ちでクリック先で本を買ってもらえると嬉しいです。
バックグラウンド
自分は集積回路設計で博士取得後、機械学習アクセラレータの研究をしてました。そのうちにコンピュータービジョン技術自体に興味を持ち、論文などを独学で読漁ってました。Kaggle参戦に役立った本、論文などは最後にまとめます。
また仕事でも機械学習用データセットやタスクなど設計してました。 しかし"動けばいい"が優先されるタスクであり、精度が求められないのがつまらない点でもありました(そもそも精度指標も自分で設計してる。。)。そこでアルゴリズムをもっと詰めてモデルを設計してみたいというもやもやはずっとありました。
始まり
D社のカジュアル面談でkaggleについて聞いたのがkaggleを始めたきっかけだったと思います。提供されたデータセットを元に、一番良いモデルを作るという明快さとモデル設計をもっと深く追い先端技術も試したいという想いからkaggleに登録した記憶があります。要はなんか面白そうだからやってみるかー!くらいの気持ちでした(今もそんな感じですが)
ちょうどKaggle勝つ本が出た頃で、本のさを読みながらtitanicをやった後、あまり考えずにそのままLyftコンペに参戦しました。
Lyftコンペ

LiDARデータから3D物体検出を行うコンペでした。Kaggleで初のLiDARデータを使ったコンペだと思います。
ただデータセット構造がオリジナルで中々本丸のアルゴリズムまでたどり着かなかったです。 自分は参加したのが終了2週間前というのもあり、PointPillarsを動かそうとしているうちに終了しました。
結局ベースラインモデルをちょっと大きくし、TTAを足したものを提出して40位の銀でした。運良くメダルが取れ、モチベーションが以後のコンペに向けて高まったのはよかったです。
いきなりソロ銀が取れた背景として問題設定の難しさからコンペ自体過疎っていてプレイヤーが少なかったのが大きいと思います。
色々穴のあるコンペでしたが*1、ロボビジョン研究者としては一番リベンジしたいコンペです。
学んだこと
- Kaggleノートブックを使ったEDA、学習
- 銀上位以上とそれ以外との圧倒的な差。
Kaggleで強い人って?
- 銀上位以上とそれ以外との圧倒的な差について補足させてください。
Kaggleコンペでは公開notebookコピペでも(運が良ければ)メダルは取れます。だからメダル二枚でなれるExpertではその人が本当に分析者として優れているかはわからない、と言われてしまうのだと思います。
ただ コピペでは超えられない壁が銀上位あたりにある印象があります。
Bengaliコンペで自分は実感するのですが、この壁を超えるのに必要なことはホストが出した問題に対し、クリエイティブな解決策が提示できるかどうかだと思います。 この点がKaggleの"競技データサイエンス"的な面で一番おもしろいポイントであり、Kaggleディスり勢が理解していないポイントと感じます。 主観ですが、データサイエンスの難問に対し独自のアプローチを取れる人は業務(開発、研究問わず)で強いと思ってます。
なのでKagglerの実力を見るときには1) コンスタントに銀上位のパフォーマンスが出せているか、2) クリエイティブなソリューションで問題にアプローチしていたかを見ると強い人かどうかわかると思います。偉そうに書いておいて自分はまだ1)は達成できてませんが。。
PKUコンペ

Outrunner氏のsolutionより
2D画像から車の3D位置と姿勢を推定するというCV的にも先端内容のコンペ。
問題設定が面白く、コーディングもなかなか難しいとやりがいのあるコンペでした。 CenterNetを使い倒し大規模2D CNNの学習を詰めれたのはいい経験でした。
PKUコンペの特徴として3D位置推定を行う既存ライブラリはないため、モデルをほぼスクラッチ実装する必要がありました。 PKUコンペを通じて自分はいくつかの論文のスクラッチ実装を行った記憶があります。 様々なアイデアをインプリするうちに 駄目駄目だったコーディングがだんだんマシになっていくのを感じました。
コンペはoutrunner氏が大差をつけて優勝しました。
Outrunner氏のカメラキャリブレーションパラメータを使って3次元回転のaugumentationを行うソリューションはとても面白く、一見の価値あり。言われてみれば確かに!と思うのだがなかなか思いつかない簡潔で有効性の高いソリューションでした。
ただ自分はネットワーク設計が最後まで良くなく(FPNを上手く実装できず)、90位の銅でフィニッシュしました。
コンペ的には色々ありましたが*2、ギリギリ致命傷にはならず最後までコンペを楽しめました。
学んだこと
- コーディング力
DNNのパラメータ調教が上手くなった。
やみくもにチームを組まない
補足です。PKUコンペではあまり考えずに0サブのNoviceの方と組んだ後、連絡が取れなくなってしまうという自体が発生しました。笑 チーム組むときはそれなりに実績ある方かスコアをそれなりに出している方と組んだほうが良いと思います。あとTwitter上で日本人の方と知り合いになりチームを組むのは(人間性、言語面)からおすすめです。またLBで銀上位につけていると結構強い人からもマージリクエストがくるようになりました。
Bengali
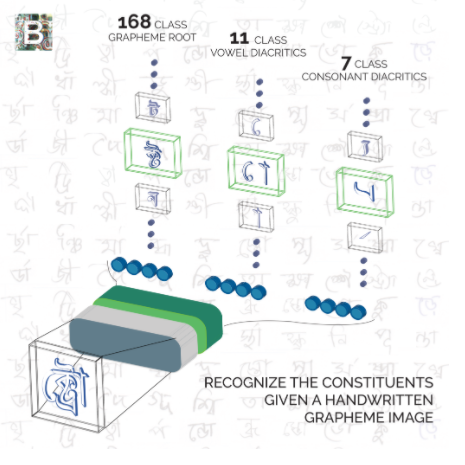
Shake Downの洗礼
Bengali文字認識を行うMNISTの延長線のようなコンペ(と当時は思ってました。) またこのコンペでは強いチームメイトと組むことができ、色々刺激を受けながら戦うことができ、とても楽しかったです。
そのため画像認識の技術を詰め込んで適当に学習させればいいや~という舐めた意識で(自分は)コンペに参戦していました。
結果としてコンペの趣旨を捉え違えていたので 49位から170位までShake Down してしまいました。

Shake Downの原因
ShakeDownの原因はコンペ説明文をよく読む・理解していないことでした。
なのでKaggleで勝ちたい、つまり運では難しい銀上位以上を目指したいならば、コンペに出る前にいくつか確認することがあります。 * 1) どのような機械学習の問題なのか?(画像、テーブル..) * 2) ホストが解きたい問題は何なのか? の二点だと思います。
例えばBengaliではベンガル文字はGrapheme, Vowel, Constantと3つの部首で構築されますが、未知なる部首の組み合わせにも対応できるような機械学習モデルを作れるか?というのがホストからの挑戦でした。
例えばBengaliでは3位のソリューションは文字がtrainに含まれていたか否かをarcfaceで判定後に未知クラスに強いモデルで判定する、1位は未知クラスはCycleGANでスタイル変換したあとに判定することで判別精度を向上させるなど特にIn-the-money圏内のチームではホスト課題にあったアプローチが多く勉強になりました。
ShakeDownを避けるために実践したこと
BengaliでShakeDownしたのはめちゃくちゃ悔しかったですし、このままKaggleをやっていても一生金は取れそうもなかったので、大きく反省し戦い方や準備の仕方を変えました。
まずホストが解きたい問題を読み取るためにコンペ説明はよく読み込む必要があると感じました。またホストがデータセットに関する論文を出していたら熟読するのが良いと思います。前述した二点目を解決するアイデアを実装できるか否かが銀上位にいけるか行けないかの分かれ道だと思います。(文章で書くと当たり前に感じますが、LBを上げることしか頭にない方も過去の(自分を含め)残念ながら多くこれを実行できている方は多くないとコンペ参加経験から感じました。自戒の意味も込めて厳し目に書いておきます。)
例えば自分は過去コンペの説明を読み込みホストの課題を理解し、上位陣がどのような具体策でその課題にタックルしたか、という視点で過去二年分くらいのコンペソリューション(上位陣のみですが)を読み漁ったのが良い勉強になりました。例えばクジラコンペやASPLOSはいい教材でした。あと強いKagglerのソリューションをまとめて読むのも勉強になります。(日本の画像系ではphalanxさんとか)
PANDA
チームアップ
Bengaliの反省後、参加したコンペでした。
このコンペではfamtaroさんやpotemanさんとつよつよなMasterと組むことができ、"勝ったな.."感はありました。
.@arutema47 さんが Master になるRTAに参加しもうした pic.twitter.com/vNaw1x2IgO
— ふぁむたろう (@fam_taro) 2020年7月5日
優勝
チームメイトではSlackで日々議論しながらモデル設計をし、特にコンペの最重要課題であるnoisy-labelに対応するかについて頻繁に議論しました。 結果的に実装したnoisy-label対策が大当たりし、まさかの優勝することができました。Goldは夢のまた夢だったので取れてかなり嬉しいです。
!?!?!? pic.twitter.com/PqygjM6oe8
— arutema47 (@arutema47) 2020年7月23日
チーム的には銀を維持して銅までshakeしなければいいな、というノリだったのでSlackでチームメイトが"1!"と送って来た時はかなり驚き、午前中は仕事になりませんでした。
優勝は出来すぎにしても、目的であったコンペ趣旨に対しオリジナル技術で対策を行いモデルを組めスコアを上げれた事はべんがりでの経験を上手く昇華することができたことに繋がり嬉しかったです。
ここでは技術的な面には触れませんが、具体的なソリューションは下記に記述してます。
また自分より遥かに優れた文才でfamtaroさんが参戦記を書いているのでそちらも御覧ください。
Winner's call
Kaggleの賞金受領手続きについて記述しておきます。 Kaggleでは賞金圏にはいるとホストへ報告書とモデル提出、そして電話会議でプレゼンするWinner's callという手続きが必要になります。
具体的な提出アイテムとして
- モデル学習、推論のスクリプト提出
- モデルについてのアプローチや考察を記述した報告書(20ページくらいのパワポ資料としてまとめ、自分はWInner's callのプレゼン資料として使いまわしました。)
の二点が必要です。両方Kaggleからテンプレートなどが支給はされますが、自己フォーマットでも筋が通っていれば問題ないです
またWinner's call自体はGoogleの会議ツールを使い組まれました。発表25分、質問30分の計1時間でした。 質問はDNNの学習パラメータ、augumentationといった技術的な話からどのような実験をして最終的なアプローチにたどり着いたか、試したが動かなかったアプローチとその考察などを聞かれました。学会のQ&Aの緩い感じをイメージしていただければと思います。お互い英語は母国語ではなかったので英語でそこまでボコボコにはされませんでした。
また賞金受領やWinner's callの手順はカレーちゃんさんのブログもとても参考になりました。(自分は個人で賞金受領したため、"W-8 BEN"をサイト上で記入しました。)
"Kaggleで賞金を獲得したら家族のために使う"と以前から宣言していたため、家族マターに有り難く使用します。笑 note.com
また本解放がMICAAI workshopへのinvite講演など学会ワークショップへ結びついたのもよかったです(こちらはfamtaroさんに投げてしまいすみません。。)
闇の小麦コンペ

闇が多すぎて正直ノーコメントです笑*3
Publicでは8位だったものの、Privateでは78/2245位までShakeDownしSilverとなりました(死)。Privateのbox特性が大きく変わってしまいそれに対応できなかったのが敗因でした。
何はともあれこのコンペを以てMasterへの昇格を"キメ"ました。やったぜ
結局小麦は10位から80位までshakeして銀でした。金がいいです..
— arutema47 (@arutema47) 2020年8月19日
何はともあれ目標のMasterになれてよかったです🙇 pic.twitter.com/ou4fbiPPHY
最後に勉強してよかった本、論文
Kaggleの参戦前に読んでおいてよかったと思う厳選書籍をいくつか紹介します。他にも機械学習系の本はたくさん買ってましたが全部売り、結局これらがのこりました。
Kaggle,機械学習の本
Kaggleで勝つデータ分析の技術

この本がなかったらKaggleのコンペ参戦まで行けていなかった気がします。
"Kaggleとは何か"から初心者用コンペのTitanic参加するまでの道のり、そして更にテーブルコンペで勝つためのテクニックが一冊にまとめられている良書です。
自分はテーブルコンペには出たことはありませんでしたが、評価指標の詳細解説や特徴量設計の章は参考になり業務でも活かせる方が多いと思います。 ただ内容は機械学習の初歩は理解していることが前提なのでこれ一冊で戦えるようになる、というわけではないです。初学者ですと下記の本一冊も同時に読んだほうがいいかもしれません。
Python機械学習プログラミング

回帰、SVM等の機械学習やデータ分析の基本を叩き込むのには良書です。会社のAI系部署の新人研修でも使われていました。 網羅している事柄も多く、最初の一冊にはかなりおすすめです。
第三版まで出てますが、ディープの内容が追加されているのが差分です。第一版でも十分勉強になります。
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

ディープラーニングを勉強するならダントツでこの本がオススメです。研究でも実務でも一番役に立ちました。G検定とか勉強してる場合じゃないですよ!
通称ゼロ作で日本発書籍ではダントツのクオリティを持ちます。
DNN、CNNの推論と学習を一からNumpyで順を追って実装する良書です。DNNの具体的な演算もイメージできるようになるので応用が効きやすく、今でもはじめの一冊としては最高だと思います。何度読み返したかわからない。。笑
NLPに興味あるならゼロ作2もオススメです。
PyTorchによる発展ディープラーニング

Pytorchで戦いたい方はこの一冊を写経するのがおすすめです。
画像認識、物体検出、GAN、自然言語処理とDNNの幅広い分野をカバーしている超良書です。
コードがとても丁寧かつ量も多く、これからpytorchを勉強しようとしている方には一番お勧めしたい本です。
Kaggleスタートブック

Kaggle勝本よりも丁寧に機械学習初心者向けにtitanicコンペについて解説をしてくれます。あまり機械学習やプログラミングの経験がない場合、この本から入りその後にkaggle勝本のステップアップするのが良いかもしれません。
個人的には機械学習プロフェッショナルシリーズ(深層学習)などは式が多くあまり技術がイメージできず、直接論文読んだほうがわかりやすかったです。
論文など
駆け出しのころに勉強したCourseraのNg先生の基本コースは参考になりました。ゼロ作を読んでも同じところをカバーできる気がします。
画像認識系の論文はそれなりに読んでいました。例えばPhalanxさんのkaggle_tipsに読んでおくと良い論文のまとめがあります。 github.com
今後の抱負
Masterになれたものの、まだまだ実力不足を実感します。今後もロボットビジョンに近いコンペに出場しながら着々と実力を付けていきたいです。
対戦よろしくおねがいします!