 Seq2seqからBERTまでのNLPモデルの歴史をざっとまとめる。
Seq2seqからBERTまでのNLPモデルの歴史をざっとまとめる。
DNNは知ってるけどTransformerってなんだかわからない、って人におすすめです。
Abst.
画像認識にもTransformerが使われることが多く、DeepRLやGPT-3といったNLPモデルも身近になってきています。"Attention is 何?"と言えなくなってきたので勉強しました。
Feedforward NetworksからSeq2Seq, Attention機構からTransformer登場、そしてBERT GPTといった最新モデルまでの流れを広く浅く記述する予定。
またKaggle NLPコンペの上位解法から利用例を探る。
Tl;DR
TransformerはSelf-Attentionという機構でデータ内の時系列的特徴を抽出でき、従来のRNNを始めとするNNに対して 100倍以上計算効率が優れる。
この優れた計算効率を活用し、近年は 莫大なデータ量と計算量で巨大なモデルを学習し、NLPモデルの精度を凄まじい勢いで改善している。
その過程で出てきたモデルがGPT-3やDeep-RLなのだと思う。
- Abst.
- Tl;DR
- フィードフォワード型NNの課題
- Seq2Seqの登場と課題
- Attentionとは
- Transformerとは
- Generative Pre-training (GPT-1)
- Bidirectional Encoder Representations from Transformers (BERT)
- Computer Visionへの応用~Vision Transformer(ViT)~
- KaggleのNLPコンペ
- Next Step
- 参考文書
フィードフォワード型NNの課題
CNN等はエンコーダとしては優れているものの、時系列情報を埋め込めないため、単語の並びは無視されてしまう。そのため翻訳など自然言語タスクでは使用できないのが課題。
例えば画像を左右反転してもCNNは犬の画像を犬と理解してくれるが、左に犬がいたか右に犬がいたかモデルは理解する術を持たない。
ちなみにDetectionでも統合的な位置関係を"理解"しているわけではない(反応したboxに応じてメタ的に情報を出せるが)。
ネットワーク自体は空間的にフィルタを適応しているだけで左右に二匹いたというコンテクストはなく、画像の意味理解を始め文章の翻訳や意味理解は難しい。

自然言語理解(NLP)では周囲のデータ(word)に対する重み付を計算する機構が必要で例えば文章理解にはeatは周囲のfoodを表すwordと高い重みをもたせたい。
この役割を果たすのがAttention であり、CV用DNNにはなかった機構である。
従来のCVでもこのような画像中の”意味理解”を果たすために、CNN+RNNを用いてキャプションを作成している。 RNNはリカレント(循環性)を持っており、単語間の特徴や単語の入力順までも含めて特徴量を抽出することができる。 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention。
Seq2Seqの登場と課題

2014年に提案された技術であり、時系列を加味したオートエンコーダのようなイメージ。
例えばエンコーダは文章を固定長のcontext vectorに変換し、デコーダはcontext vectorを別ドメイン(中国語)の文章に変換する。
NN自体のモジュールとしてRNN, LSTM, GatedRNNなどが使われるが本記事では深追いはしない。 過去と現在といった時系列のデータを上手く扱えるようにしたNNモジュールと思えば良い。
ゼロから作るディープラーニング2に丁寧に原理や実装方法が載っているので興味のある人は読んでみて下さい。
Seq2SeqやRNNの課題:
RNNは順次にデータを入力し処理するが長い文章を入力すると最初の方の文章について”忘れてしまい”、文章全体の理解は難しい。
- Context Vecは単一の固定長ベクトルであり、保持できる情報量は限りあり
- これを長くすると今度は短文の理解が難しくなるというトレードオフ
隠れ層で"前状態"の特徴も伝搬させていくものの、限度がやはりあり例えばブログ記事全て(1000単語)などを理解させるのは困難。
Attentionとは

Self-Attention Mechanisms in Natural Language Processing | by Alibaba Cloud | Mediumより

Attentionは人間の目の仕組み(Visual Attention)からインスパイアされたNNの機構である。
考え方:
目はあるパーツを見ている時に共に周囲の関連する画像部位を"低解像度"で見ることで、画像全体の理解を図る。
この"低解像度"でみることはある重みで周辺データを加算することと同義であり、この仕組をDNNに取り入れた。
例えば画像の柴犬の耳(黄色箱)を見ているとき、人間の目は周囲の耳や鼻も低解像度で見ており、犬全体のコンテクストも理解している。
Attention(初期)の実装
Attention初出:Neural Machine Translation by Jointly Learning to Align and Translate

RNNの各隠れ層の状態からContext Vectorに作用させるショートカットを作成している。
- AttentionLayerがEncoderの各隠れ層から単純に全結合で情報を取り、Context Vecとさせる。
- RNNのエンコーダ隠れ層Ht全てを利用し、ContextVec.を入力に依存した行列にする
そうすることで文章全体から特徴量を効率よく抽出可能。
デコーダはデコーダRNN出力+EncHtの特徴量両方を使い出力計算する。
Transformerとは
初出:Google, Attention is All you Need NLPで間違いなく最も有名な論文で初学者でも読みやすかった。
Googleが出すgame-changingな論文は(EfficientNetとか)とても読みやすい。 奇を衒わなくてもトップ学会に通るポテンシャルがあるからか。
従来モデル(seq2seqとRNN全般)の課題

RNN系NNモジュールは前ステートの状態を受け取らないと計算を始められない。
すると計算の並列化は本質的に難しく、計算が遅いのが最もクリティカルな課題。 (要はGPU計算効率が低く、たくさんのデータで学習できない)
例えばn入力=(x0, x1, x2, x3, .. xn)あったとき、RNNが隠れ層=(h0, h1, h2, h3..hn)を計算するためにはnステップが必要である上に例えばh2はh0とh1に依存し計算を並列化する事ができない。単純に言うと 計算時間がO(n) となってしまう。
バックプロパゲーションを間で切るというテクニック等で並列化・高速化もなされてきたが、シーケンスが長いと情報量は落ちてしまうし本質的な解決にはなっていなかった。
革命はなぜ起こったか?

私にいい考えがある
RNNをベースとした構造からTransformerではAttention(正確にはSelf-Attention)をベースとした構造に進化した。

Self-Attentionは入力ベクトルのみから出力を並列計算で導出可能で計算依存性がなく、GPU計算に向く。 十分に並列ハードウェアが使用可能ならば 計算時間はO(1) である。
またそもそもSelf-AttentionはRNN、CNNセルよりも計算する要素が少なく高速である。 n=10, d=512のタスクと考えると Self-Attentionの計算量は50倍少ない。

実際Transformerの論文ではRNNベースの手法と同等精度に達するために必要な演算量は 100-1000倍少ない と報告している(そして計算時間は更に高速)。
このようなAttentionベースの構造、 Transformer をGoogleは提案し、NLP精度に革命を起こした。
DNNはそもそもデータを学習時に喰わせれば喰わせるほど精度を向上できる性質を持つ事を思い出したい。
Transformerというリカーレントな特性を持ちつつ並列化に向いたモジュールを提案することで、NLPモデルにより多くのデータで学習可能となりモデル精度が爆発的に向上したと自分は思ってます。
Transformerブロック図

まずはアーキテクチャとしての動作を見てみる

アーキテクチャ全体の概要はGPT-1論文の図がわかりやすい。
イメージとしてN入力に対しTransformerEncoderをそれぞれ計算し、N個の特徴量を抽出という点はSeq2SeqやRNNと変わらない。
しかしTransformerEncoderは依存関係がなく、GPUでN並列で計算が可能である点が革新的であった。N個のコアがあれば1回のステップでTransformerは計算が終了するため、RNNよりN倍計算が早い。
そしてデコーダにも前述した特徴量を入力し、エンコーダとほぼ同等に並列で高速計算が可能である。
Transformerブロックとしての動作
論文を見るに非常に単純で基本的にはSelfAttention→(ResidueとAdd)→FC→(ResidueとAdd)しているだけ。
PytorchのTransformerEncoderLayerソースコードを見てみよう。 https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/transformer.py

forwardはとてもシンプル。 それだけself_attentionが強力ということだろう。
ちなみに元論文ではこのエンコーダを6回Stackしている。
Self-Attentionとは

Transformerの要は間違いなくSelf-Attentionである。
self-attentionではあるベクトルX=(x0, x1, x2, x3, xn)が与えられた時、Xに対しまずクエリとキーを計算する。
そしてアテンションαをクエリとキーの内積結果から算出する。このクエリとキーの演算によってXと重みクエリとキーの類似度を計算している。
そして最後にバリューを計算し、アテンションの結果を重み付けした値を得る
TransformerにおけるSelf-Attentionは Scaled Dot-Product Attention という方式を利用。(他にもたくさん計算方法はあるが、現状はこのAttentionが寡占しているよう。)
計算はシンプルで以下である:

計算のフロー: queryとkeyに対し内積をとり正規化後に非線形化(softmax)し、最後にvalueと内積を取る。
復習: 式をみてもイメージが沸かない人は内積の意味を思い出そう。内積はベクトル同士の類似度を取ること。
考え方: まず各keyそれぞれにおいてQueryのどこと類似性が高いか計算する。 Attentionのそもそもの考え方は入力(key)と類似度が高いデータを取り出したい、というものだ。 特にCNNのようにフィルタで計算し抽出するわけではなく、あくまで自己のデータ性質に注目し出力を作る。
Q K と計算した類似度の高い(注目するべき)領域をVと更に内積を取ることでデータを抽出しているイメージ。
このようにkey,query, valueが同一データから来ているため"self"-attentionと呼ぶ。 こんなにシンプルな仕組みが強力の結果を生むというのは驚きだ。
(うーん、よくわからん!となったら最初の柴犬の例を思い出してベクトル内積を復習してみると良いかも。)
重要な事はGPU的には内積演算は非常に効率よく処理することができ、Transformerの全てのブロックはGPU-friendlyであるという点だ。
MultiHeadAttention

実際にTransformerで使われるのはSelf-attentionを発展させたMulti-head-attentionである。 Self-Attentionを複雑にして表現力を増したものと考えると良い。
Self-Attentionと違い、Multi-head-attentionでは学習する重みが出てくる。
- 考え方:
V,K,Q全てを全結合層でh次元に変換し、h個のAttention機構に入力する。
そしてh次元の出力をconcatし、全結合で元の次元に戻す。
h個に次元を拡張するため、multi-headと呼んでいると思う。
- なぜこんな事を?:
" Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions "
感覚的にはこちらの方が表現力が増える、という事を元論文では記述しており元論文ではh=8を採用している。
Generative Pre-training (GPT-1)
OpenAI, "Improving Language Understanding by Generative Pre-Training"
 アーキテクチャ的にはTransformerを活用しているが、Transformerエンコーダのみの構造になりDecoderはなくなった。
アーキテクチャ的にはTransformerを活用しているが、Transformerエンコーダのみの構造になりDecoderはなくなった。
どこがブレイクスルー?
学習方法にGenerative Pretraining、一種のsemi-supervised learningを活用することで大幅な精度向上が可能な事を示したのがブレイクスルーであった。Generative Pretrainingは後続のGoogle BERTといった研究にも大きなインパクトを与えた。
文章生成のリアルさが凄く、GPT-3では人間を騙せるレベルになり話題になった。
学習は大量のデータを活用するゆえに長いものの、一度Transformerをpretrainしてしまえばfine-tuningで様々なタスクに転用可能であることを示した。
Generative Pretrainingって?
DNNは大量のデータを食わせることで精度を増すが、大量のラベル付けデータを用意するのは難しい。
しかし自然言語ならば大量のラベルなしだが人間が記述した良質なデータは手に入る(Wikipediaなどを見てみよう)。
例えばこのような文章を収集したとする。
吾輩は猫である
そこで収集した文章にわざと穴あきを作り、その穴あきに何が入るかモデルを当てさせモデルを学習する。
吾輩は○である
このような学習方法(教師なし学習)により、文章データさえあれば 学習データをほぼ無尽蔵に生成できる 。
この手法をgenerative pre-trainingと呼ぶ。

計算効率を向上させたTransformerと無尽蔵の学習データを生成するGenerative Pre-trainingによりNLPモデル精度は凄まじい勢いで2018年から伸び始めた。。

GPTでは事前学習したTransformer自体はそのままに変えず、タスクによって入力方法や大枠のアーキテクチャを変更することで使い回す。
GPTは 教師なし学習でTransformerを学習(Pretrain)し、最後に貴重なラベル有りタスクに特化したデータで ファインチューニング するという現代NLPモデル学習の基礎を確立した。
例えば、大体KaggleのNLPコンペをやる時はGoogleが公開しているPretrained-BERTモデルをダウンロードし、タスクに応じてアーキテクチャを組むという流れだと思う。
Karpathy兄貴のMinGPT
ミニマルなGPTのコードが公開された。これを読むのがわかりやすいかもしれない。
GPT-1 vs GPT-3
アニキのREADMEによるとGPT-1とGPT-3の差は
GPT-3: 96 layers, 96 heads, with d_model of 12,288 (175B parameters).
GPT-1-like: 12 layers, 12 heads, d_model 768 (125M)
と1000倍ほどモデルサイズが異なる点であると思う。もちろん学習時間も1000倍かかる..
Bidirectional Encoder Representations from Transformers (BERT)
Google, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
神論文2。みんなで読もう。
Transformerの課題

サイバトロン戦士、トランスフォーム!出動!!
Transformerは強力で高速なものの、時系列情報はあまり強く学習できない。
文章単体ならば強力にできるが、例えば数千単語に及ぶ文章の意味理解は難しい。
Bi-Directional Transformers


- Transformerを双方向にしたものを提案。
- Attention機構のようにエンコーダ隠れ層全てを使っている
- Seq2SeqのDecoder機構は使わずに実装。
GPT-1で提案されたpretrainingを適応し、更に精度向上。
名前の由来。。
ELMoへのリスペクトからか、NLPはセサミストリートのキャラ名をもじったモデルが多い笑
Computer Visionへの応用~Vision Transformer(ViT)~
Vision Transformer 原題:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scaleという研究で画像認識にTransformerを使いSota CNNと同等の精度を達成したことが話題になりました。
Vision Transformerの論文では画像を16x16の切れ端にcropし、それを"単語"として見てTransformerに入力します。 そこから論文のAn Image is Worth 16x16 Wordsというネーミングが来ています。画像も単語のように扱えるよ!というNLP→CVに技術が浸透した面白い例ですね。
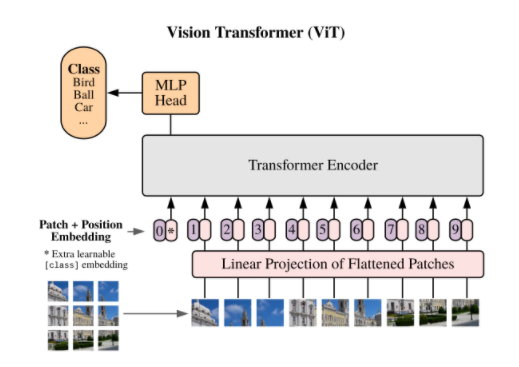
Transformerのアーキテクチャは変えずに(ネットワーク自体はBERTとほぼ同等)、画像の入力方法を工夫することでCNNと同等のImageNet認識精度を達成するネットワークを実現したことから大きく話題になりました。

ViTは信号処理的には16x16のstride16 convolutionを初段で噛ませ、次段以降は全てのパッチ情報を加味した特徴量抽出になっている。初段はCNNに似ているが、次段以降は全く違う処理という議論。https://t.co/vj5N1KpxgO
— arutema47 (@arutema47) 2020年10月13日
ViTの初段はConvolutionと同等の処理をしますが、次段以降は全てのImagePatchの情報を組み合わせ特徴量抽出を行うので従来CNNとは動作が大幅に異なります。 そのため今後もCNNでは到達できなかった精度やタスクを実現できる可能性はあり、今後の発展から目が話せません。
[追記]
CIFAR-10でViTを学習させてみました。
やはり巨大なデータセットでpretrainしないと性能は出ないようです(resnet18なら90%出るところ、ViTをスクラッチから学習すると80%程度しか出ない)。 GoogleのViTモデルで転移学習した場合、99%精度出ることが確認されてます。
KaggleのNLPコンペ

いきなりソリューション読んでもちんぷんかんぷんなのだ。
小学生並の感想ですが、NLPはfeatureエンジニアリングや前処理、後処理エンジニアリングが効く部分が多く、Tableコンペ強勢に人気ありGMが台頭するのかなと思ったり。
GMが多いコンペはいいコンペ。
Google Q&A
ぐちおさんのブログが素晴らしいので読んで下さい:huggingface:
FacebookのRoBERTa、BARTなどが精度ー計算量のバランスが良く、たくさん使用されている
https://www.kaggle.com/c/google-quest-challenge/discussion/130047
huggingfaceという会社が出しているTransformer, BERTはTockenizerといったNLP前処理関数が使いやすく幅広い参加者に使われているみたい。
Tweetコンペ
これもぐちおさんのブログがとてもわかりやすいのでry
とてもわかりやすく闇と光:huggingface:がまとまっていました。
上位解法を読むとデータ前処理、ラベル処理に芸術が隠されてそう。 (アノテーションずれしたデータを渡すのは正直どうかと思いますが)
一位解法

どうStackingしてるんだろう笑 Transformerの特徴量を1x1 CNNに渡し分類器を構成しているんだろうか
Jigsaw
読んでない。
Next Step
いきなりBERTに手を出してもろくなことにならなそうなのでゼロ作2を元にSeq2Seqを実装し、Transformer実装まで行きたいと思います。