dToF/iToF LiDARセンサの原理や製品について

記事の目的
本記事ではdToFとiToF LiDARの基本や原理について説明します。 また込み入った理論ではなく、LiDARの大まかな種類や用途を理解するのが目標です。
LiDARセンサはLight Detection and Rangingの略で光を使った距離測定技術の総称です。 RADARが電磁波を使って距離を測るのに対して、光を使った距離センサを指します。
こちらは距離センサ全般の記事です。合わせてどうぞ。 aru47.hatenablog.com
LiDARには大きく2種類ある
LiDARには大きく2つ種類があります。
一つはdirect Time of Flight型(dToF) LiDARでもう一つがindirect Time of Flight(iToF)型LiDARです。iToFは間接ToF型とも呼びます。
dToF LiDAR
原理
距離センサ入門からの引用です。
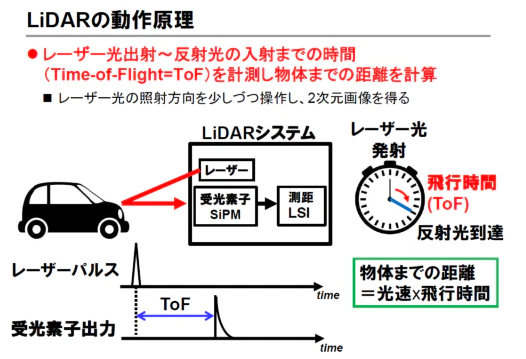 dToF LiDARはレーザパルスを出射し、筐体に帰還するまでの時間から対象物までの距離を求めます。
dToF LiDARはレーザパルスを出射し、筐体に帰還するまでの時間から対象物までの距離を求めます。
dToFの原理を考えてみましょう。 LiDARはTime of Flight(光の飛行時間)をベースにして距離を測ります。
原理としては単純で、下記の図のようにパルスレーザを筐体から放ち、そのレーザパルスが物体に反射して返ってくるまでの時間を計測します。
もしレーザ光が10秒後に返ってきて光速を単純のため1m/sとすると、物体までの距離は
(10秒 * 1m/秒)/2 = 5m
と5m先に物体があることがわかります。
このように直接飛行時間をベースにして距離を導出するのでdirect Time of Flightと呼びます。
実際の光速は108m/sと非常に早いため、光が返ってくるまでの時間は数ピコ秒、ナノ秒のオーダーなので時間を計測する回路には高い精度が求められます。
dToF LiDARの製品
- Velodyne LiDAR

- Livox LiDAR

n
ちなみに、Livox Horizonは10万円で入手可能です。
dToF LiDARの特徴は以下です:
- 遠距離
- 外乱に強い
- 価格は高い
いずれのLiDARも距離は50-200m、角度解像度は0.1度~1度程度です。 そのため自動運転など野外の距離測定用に注目されています。
例えばWaymo社の車の上などにdToF LiDARが載っていますね。ちなみにwaymoのlidarは自社製(!)です。
よく見るクルクル回転する機構を備えており、それによって360度の全周囲のデータを獲得しております。

またLivox LiDARは安く、ドローンなどのアプリケーションへの適応も期待されています。
dToF LiDARの種類について
(2022/7追記)

Gates-backed Lumotive upends lidar conventions using metamaterials – TechCrunch
こちらの図はdToF LiDARの種類を3つに分けております。
2D Raster-Scan型や1D Line-Scan型は単位画素辺りのレーザパワーが高いため、計測距離が長いのが特徴で自動運転に必要な200mを達成可能です。一方で弱点としてレーザのスキャン機構が必要のため、価格は高いです(数十万円)。
そのためiPadなどのコンシューマーデバイスではFlash型というスキャンをしないLiDARが使われています。Flash型はカメラのフラッシュのように一面にレーザを照射し一度に多くの画素のdToF計測を行います。画素辺りのレーザパワーが弱いため遠距離は取れませんが、スキャン機構がないため低コストかつ小さい筐体で実現可能です。
iPadのdToF LiDAR
(2020/6/18追記)
アレーサイズは320x240?のFlash型LiDARを形成しています。Flash LiDARはレーザを一面に照射し、イメージセンサのように一度に絵として反射レーザを受光しToFを得る機構です。Velodyneのようなスキャン型に対しレーザ光が分散してしまうので距離は取れないですが、室内であれば十分実用的な結果が得られます。

SPADはマイクロレンズ付きの10umピッチで裏面照射型となっています。チップ写真を見る感じ、SPADアレーであるチップと読み出し回路をCu-Cuで接続している3Dチップです。読み出し、ToF計算回路はいつものCISで使用している10メタルプロセスの65nmのCMOSロジックチップでしょうか。
indirect Time of Flight
原理
ようやく本題のiToFについての説明です。ただその理解のためにはdToFの原理を理解している必要があったため、説明に時間を割きました。
iToF LiDARは原理としては光の飛行時間を用いていますが、パルスのズレではなく間接的に飛行時間を測定します。
じゃあその間接的ってなによ?というのがキモとなります。


https://www.terabee.com/a-brief-introduction-to-time-of-flight-sensing-part-2-indirect-tof-sensors/
図にiToFの原理を示します。
dToFではレーザパルスを送信していたのに対し、iToFでは周期的なレーザ光を放出します。(sin波など)
そして対象物までの距離に応じて位相がずれた波形が返ってきます。
LiDARは受信した波形の位相を判断し、対象物までの距離を計算できます。
LiDARの周期をt、光速をc、検知した位相遅れをθとすると、
distance = c/2 * t * θ/2π
となります。ちゃんと光速をベースとしたTIme of Flightの式になっているところに注目していただけたらと思います。
iToF LiDARの製品
- Kinect v2, Azure Kinect




https://annex.jsap.or.jp/photonics/kogaku/public/41-05-kaisetsu1.pdf 画素内積分回路の実装
回路の話となりますが、dToFのようなパルスレーザを高精度に受光する回路は複雑になってしまう反面、iToFのように周期的なレーザ光の位相を計算する回路は非常に小さく設計することができます。 具体的には位相の計算処理はアナログ回路が得意な積分回路で実装することができ、実際にソニー、マイクロソフトの製品では同処理を特別な画素を設計し、ピクセルレベルで行っております。
追加回路は多く必要がないため、そのためイメージセンサと同様な回路を設計することができ、非常に大きい解像度を持ちながら(0.1-1メガピクセル)コンシューマデバイスなどに載る低価格なLiDARを作ることができるのがiToF LiDARの特徴です。 iPadProに使われているチップはSony IMX556のカスタム、廉価バージョンなのではないかと予想しています。多分原価はX000円程度に押さえているのではないでしょうか?受光素子自体はイメージセンサと同様に大量生産でき、機械部が存在しないため価格を抑えられ手軽な値段に抑えられるんですね。
iToFの良いところを述べましたが、もちろんdToFに対してデメリットもあります。大きな原理上のデメリットとしてiToFではレーザ光の変調周期は最大距離と距離精度のトレードオフとなるため、長距離のデータを高精度で取るのを苦手としています。例えば100MHzで変調させると最大距離は約15mと限定的です。 また1ピクセル辺りの出射レーザ光パワーが低いため、十分な精度が得られるのは10m以下と野外での使用は厳しいです。
また最後に半導体には馴染みない方にはマニアックに感じるかもしれませんが重要なのがセンサ(フォトダイオード)の要件です。このように積分結果から距離を導出するため、フォトダイオードの特性は線形でないといけません。 しかしながらフォトダイオードを線形の領域で使うと受光効率は悪く、弱いレーザ光を検出することはできません。反面にdToFでは光を検出さえできればよく受光特性は非線形でも精度に寄与しません。そのためフォトダイオードの受光効率が高いアバランシェ領域やガイガー領域で動作することができます。この領域における受光効率はiToFに使用する領域の数100~1000倍ほど高いです。だからdToF LiDARは数百メートル先の物体を検出できるんですね。
参考文献
- パルス変調型iToF(ソニー)
- ミキシング型iToF(Microsoft Kinectv2, v3)
- 解説記事
この分野の権威である静岡大川人先生の解説記事です。とてもわかり易く、オススメ。
自分の論文の日経エレの解説記事です。有料ですが。。
最後に
LiDARにはdToFとiToFと2つの原理があって使用されている製品が全然違うんだなあーというのが理解していただけると幸いです。
これからiPhoneなどにも載ってくると思うので距離センサはどんどん身近になっていきそうです、その時どういうアプリケーションが出てくるか楽しみですね。
Tracking Objects as Points (CenterTrack)


なんの論文?
CenterNetの著者からの最新論文。CenterNetと同様にシンプルなアプローチながら、有効性や応用性が高く様々な研究で使われるようになりそう。
前作CenterNetはPointを用いた物体検出であったが、今回は同様のPoint-baseのネットワークでトラッキングの提案。
従来Deepトラッキング系の研究よりも高速、かつ高精度を実現。
著者のAbst.が端的で面白い。
"Our tracker, CenterTrack, applies a detection model to a pair of images and detections from the prior frame. CenterTrack localizes objects and predicts their associations with the previous frame. That’s it. "
おそらくECCVへの投稿。
追記: 2020/11/4 ECCV2020にて採択されてます。
従来
従来のDeep tracking系は画像物体検出を別ネットワーク(Faster RCNNなど)で実施、 その結果と特徴量をトラッキングネットワークに入力しトラッキングを実施していた。 このような手法を著者らはTracking by detection (物体検出ベースのトラッキング)と呼んでいる。
例えばSORTであればカルマンフィルタで物体のトラッキングを計算し、DeepSORTでは物体の特徴量も用いて検出を行っていた。
このような手法でも精度は高かったが、別々にネットワークを学習しなければならなかったため1)速度が遅い、2)全体ネットワークが複雑で最適化しづらいという欠点があった。
提案

CenterTrackは前フレームと当フレームの2枚のペア画像+前フレームの物体情報(Tracklets)のみ入力とし、高精度なトラッキングを実現。
CenterTrackは検出結果、物体サイズ情報、そして点がどう動いたかというオフセット情報を出力する。 たったこれだけの情報で、高精度なトラッキングが実現でき学習が上手くいくというのは驚き。
ただ本文中でも学習時のデータの与え方には工夫が必要と書いている。何も考えずに学習してしまうと前フレームしかネットワークに入力しないため物体が動いていないと出力しても十分ロスは低く、学習が進めない。
著者もネットワーク自体はほぼCenterNetと変わらないが、Augumentationや学習時の工夫がないと上手くこのモデルは動かないと書いている。 学習を上手く進めるためには1)アグレッシブなデータアーグメンテーション、2)False NegativeやFalse PositveのTrackletsを恣意的に与えて学習する、という新規ポイントを加えており、それが論文的に面白い。
興味深い手法
Tracking data augumentationの部分(4.4 Training on static image data)が非常に興味深く、実務上も有用だと思うので紹介する。
トラッキング用の学習データを作ることは難しい。例えばビデオデータにおいてある物体がどう遷移しているかというデータセットを作る手間は非常に大きく、画像認識等と比べ大量のデータを用意するのは難しい。 このデータセットを作る難しさのおかげであまりトラッキング用データセットは世になかったため、DeepTracking系はあまり画像の研究として盛り上がっていなかった。(個人の感想です)
一方CenterTrackの論文では一枚の画像をshift-rotateすることで擬似的に前フレームを作り出し、ビデオデータなしにtrackerを学習が可能にした。 またこのAugumentation時に物体を大きく動かすことでネットワークのトラッキングに対する汎化性能が大きく上がり、高精度化に最も寄与したとのこと。
著者らはMS-COCOのデータセットを元にトラッキングモデルの学習を実現している。(画像中でネクタイのトラッキングが実現できている!) この画像データセットから高精度トラッキングネットワークが学習できることは大きなブレイクスルーであり、インパクトはかなり大きいのじゃないかと思う。
ステレオカメラの原理、信号処理について
はじめに
ステレオカメラの信号処理について詳細に記述しているメディアは少ない。 一方で現行のステレオカメラで最高の精度を誇るEnsensoのwhitepaperは非常に参考になる。
Obtaining Depth Information from Stereo Images

原理
ステレオカメラ自体の原理はシンプルで、人間が距離を認識するのと同様の"視差"の概念を使用する。
左センサで見た物体が右センサで見た時、何ピクセルズレているかに応じてセンサから物体までの距離が算出できる。 この視差をステレオカメラでは"Disparity"と呼ぶ。
課題

- 歪み
一方でイメージセンサで得られた画像はレンズなどにより歪みが生じる。 歪があると左右のセンサで物体位置がheightによりズレてしまい、disparityを計算できない。

この画像では左右の画像で歪みが生じてしまい、左右センサでかなり指している画素位置が異なってしまう。 これでは効率よく計算できないため、歪を取り除く必要がある。 このような歪みはレンズキャリブレーションと同様、レンズ曲を打ち消すような逆関数を画像に掛けることで取り除くのが一般的である。
- オフセット

歪みのような非線形な誤差をレンズキャリブレーションで取り除いても、今度はセンサ設置取り付けの誤差などで左右の画像間で高さや回転誤差が生じてしまう。このような誤差は画像を回転・平行移動してやることで取り除くことができる。
- マッチング
また距離を推定するには左センサの画素が右センサのの画素と同一かマッチングを取る必要がある。 このような処理をcorrelation matchingと呼び、間違えると完全に違う距離を推定してしまう。このような画像処理はステレオカメラで最も難しく、精度や画質に大きな影響を与える。(例えばintel real senseなどは安価で良いセンサなのだが、マッチング処理が甘く大きく画素欠けが発生してしまい工業用途には厳しい。)
キャリブレーション
一般的には撮影前のキャリブレーションにより歪みは大きく低減可能である。 具体的には上記の歪み、オフセットを除去するための逆関数・回転行列を求めるのがキャリブレーションの目的となる。
歪を左右のセンサで極小化するため、ステレオカメラではキャリブレーションが非常に重要となる。 例えば数ピクセル分だけセンサ間でズレが生じたとしても距離にして数mmもズレてしまい、工業用途には適さない。 そのため高精度ステレオカメラを購入したら必ずキャリブレーションを行おう(ステップが多くかなり大変だがガイドラインが必ずあるはずだ。。)
まだキャリブレーションの手法などについては調査中。
Recitify

recitifyは本来では整流と信号処理では使用するが、ステレオカメラでは左右センサの歪を除去した画像の事を指す。 例の図中の一番下の画像は左右で歪み、オフセットが取り除かれており、recitified imageと呼ぶ。
Stereo matching

左右のセンサで捉えた画素が同一物体を指している場合のみ、disparityを導出できる。
そのためには物体が同一かどうか判定するMatching処理が必要になる。 このことについては後に追記する。
PointPillars技術について
PointPillars: Fast Encoders for Object Detection from Point Clouds
PointPillarsとは2018年に提案された3D物体検出技術、または点群ニューラルネット技術です。
従来技術よりも高速かつ遥かに高精度で精度ー計算量のバランスが良く、現在多くの3D物体検出研究はPointPillarsを改良したものとなっております。
有名所ですと例えばAutowareに実装されていたりしますね。
課題

従来点群のみ使用したネットワークは精度は高いが低速で、点群を画像に投影するネットワークは高速だが 精度が低いという欠点があった。
提案
 狙いとしては点群の細かい情報量を失わないように情報量をエンコードし、疑似画像に変換する。その疑似画像を2D CNNで使用するような物体検出ネットワークに入力し、物体検出を行う。
この手法の進歩性は従来単純に点群を俯瞰画像といった疑似画像に投影し物体検出CNNに入力するだけでは点群の細かい情報量が失われてしまっていた。そこで点群を画像に投影するためのエンコードネットワークを用いることで点群情報を失わずに物体検出CNN(SSD)に入力データを与え高精度化を達成した。
狙いとしては点群の細かい情報量を失わないように情報量をエンコードし、疑似画像に変換する。その疑似画像を2D CNNで使用するような物体検出ネットワークに入力し、物体検出を行う。
この手法の進歩性は従来単純に点群を俯瞰画像といった疑似画像に投影し物体検出CNNに入力するだけでは点群の細かい情報量が失われてしまっていた。そこで点群を画像に投影するためのエンコードネットワークを用いることで点群情報を失わずに物体検出CNN(SSD)に入力データを与え高精度化を達成した。
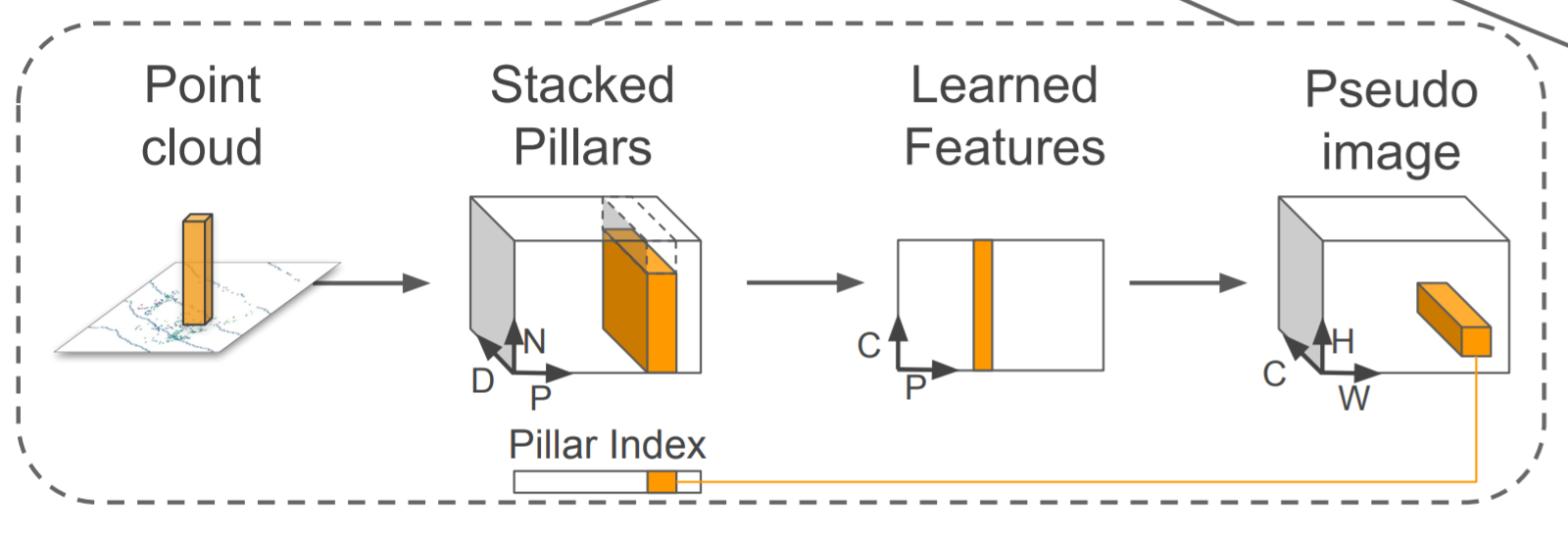 具体的に点群を画像にエンコードするために、Pillar(柱)と呼ぶ点群を細かく格子状に分割しPointNetのような点群DNNを使いPillar内の特徴量を抽出。そして得た2Dの特徴量マップをSSDに与えることで物体検出を行う。
アイデア自体は非常にシンプルながら、PointNetと物体検出CNNを結合する手法を初めて提案し点群物体検出の精度でブレイクスルーを果たした。
具体的に点群を画像にエンコードするために、Pillar(柱)と呼ぶ点群を細かく格子状に分割しPointNetのような点群DNNを使いPillar内の特徴量を抽出。そして得た2Dの特徴量マップをSSDに与えることで物体検出を行う。
アイデア自体は非常にシンプルながら、PointNetと物体検出CNNを結合する手法を初めて提案し点群物体検出の精度でブレイクスルーを果たした。
実験
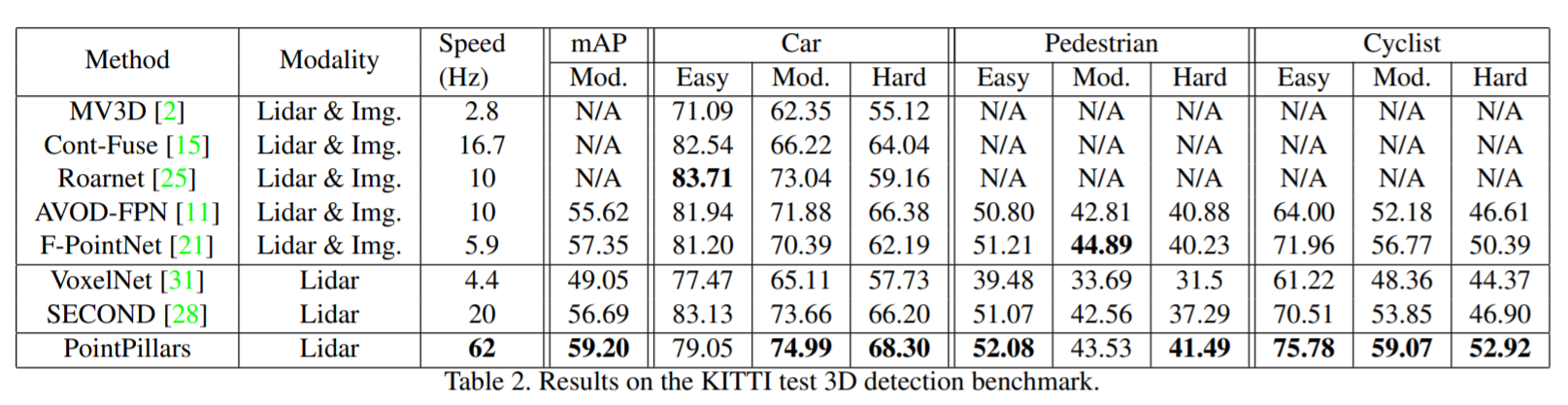 発表当時、KITTIベンチマークでstate of the artを達成。
発表当時、KITTIベンチマークでstate of the artを達成。
ネットワーク自身も改造しやすく、Kaggleなどのコンペでも頻繁に使われている。
https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles
Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection
Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection
https://arxiv.org/pdf/1908.09492.pdf
現在のNuscenes一位のソリューション。

課題
LiDARデータのaugumentationの提案が主に精度向上の要因。
Nuscenesはクラス間精度の平均が評価指標になっているが、学習データ数がクラスによっては異常に少なく学習が進まない。例えば最も頻出する車クラスに対して人やanimalクラスは1/10から1/100しかない。

提案
 このようなデータセットインバランスに対応するため、点群データ中に少数クラスを恣意的に生成することで学習を進みやすくした。ネットワーク自体はほぼPointpillarsの応用で、データセット拡張により大幅な精度向上を実現した。
また精度に貢献している提案として大きさなどが似ているクラス(人と自転車など)を"superclass"としてまず分類してから詳細クラスを分類する2-stepの分類を実行している。
このようなデータセットインバランスに対応するため、点群データ中に少数クラスを恣意的に生成することで学習を進みやすくした。ネットワーク自体はほぼPointpillarsの応用で、データセット拡張により大幅な精度向上を実現した。
また精度に貢献している提案として大きさなどが似ているクラス(人と自転車など)を"superclass"としてまず分類してから詳細クラスを分類する2-stepの分類を実行している。
結果

Learning in the Frequency Domain
Learning in the Frequency Domain
 https://arxiv.org/abs/2002.12416
https://arxiv.org/abs/2002.12416
Alibaba
CVPR 2020 accepted
課題
入力画像を空間領域で扱うのはファイルサイズが大きいため、従来ネットワークは224x224x3と小さいサイズに変換。元の画像サイズ(440x440x3)に対し空間分解能が減り、情報量が減ってしまう。
提案
NNの入力を周波数領域(JPEG規格で扱うDiscrete Cosine Transform DCT)にする。等価的に大きい解像度の画像を周波数領域に変換し直接DNNに入力。DNNの性能に効くDCTチャネルのみ使用することで、入力データ量を一定に保ちながら従来画像入力時よりもDNNの精度が向上できることを実証データ量を半分にしても、Imagenet精度は高くなることを示す

精度に効くチャネルを選択する手法がシンプルながら有効性が高い。

手法
 DCTデータを直接ネットワークに入力。最初のCNNレイヤを取り除いている。これで上手くいくのは驚き。
DCTデータを直接ネットワークに入力。最初のCNNレイヤを取り除いている。これで上手くいくのは驚き。
実験
画像認識だけではなく物体検出タスクにも応用可能なことを示した。
今年読んで楽しかった技術書10冊
今年読んで楽しかった技術書10冊
リスト
コメント
脳・心・人工知能 数理で脳を解き明かす
日本が誇る人工知能学者の甘利先生の本です。1950年代の脳・人工知能の歴史から丁寧に、先生自身が体感された当事者目線で書かれています。
いつものAI本にある”2012年にヒントンがーディープラーニングがーヒ敗男ー”な人工知能本はかなりウンザリですがこの本は一味違いました。
第一次人工知能ブームではどのような研究が盛り上がっていたか、第二次ブームまでにどのような進歩があり学会のフォーカスが変わっていったかについて書かれており、学びが多いです。また本線の数理で脳を解き明かす点についても理系でなくてもわかるように書かれており、ディープラーニングから入った新参者でもどのようにニューロモデリングが発展してきたか一歩一歩わかるため面白かったです。
意味がわかる統計解析
恥ずかしながら学部から統計についてちゃんと勉強した事がなかったため、入門書として買いました。 統計で重要な用語を新参者でもわかりやすく説明しているため、入門書としては◎。ただ式や導出などは一切ないため、この本だけで実務をするのはむずかしいかと。
本書を読んでから詳細な理論を勉強するために東大統計本に移りましたが、大枠なイメージがあるかないかで全然理解が違いました。
決算書分析2020
株をやっていると企業の財務分析は必須なんですが、教育を受けないと企業の財務諸表は読める気がしない。
本書は実際の企業資料(キーエンスやソフトバンク)などを使い説明してくれるため、非常にわかりやすかったです。 財務諸表は読めると非常に楽しく、企業の本当の形が見えてきて楽しいです。いつかブログでも財務諸表リーディング記事を書いてみたいな。
つくりながら学ぶ! PyTorchによる発展ディープラーニング
PytorchでSSDやTransformerをスクラッチから書いてみよう!という機械学習やDNN経験者向け書籍です。 会社でもpytorch入門に使っており、レポのコードがコメントが多くとても追いやすいです(SSDの実装はコメントがあまりなくて初心者には辛い。。)またGANや自然言語はやったことなかったので、実装することで理解が深まり諸論文も読めるようになって楽しかったです。
日本語で学べるPytorch入門本としてはベストだと思います。
Kaggleで勝つデータ分析
Kaggleってなんかスゲー人の巣窟で怖いなあ(某GMとか)、と思ってたのですが入門本を読んで実際にTitanicなどしてみることでデータ分析コンペが身近に感じられました。”勝つ”テクニックも業務に転用できるものが多く、データ分析本としてもトップクオリティを誇ります。
この本を読んで参加した初Kaggleコンペ(Lyftコンペ)でもソロSilverメダルを取ることが出来てよかったです。 来年中にもっとランクを上げたいけど時間が全然取れない。。
ちなみにmy kaggle垢はこちらです。フォローなどどうぞ。
雑感
ハード寄りの本はあまり読まなかった一年かも。 専門であるアーキやLiDAR、ロボットについてはほとんど論文からインプットしているのもある。
ソフト、データ分析は良書が多いというのもありますね。 その分駄目な本も多いですが。。東大データ分析本とかは自分的にNGでした。
アーキなんてヘネパタしかないしLiDARに至っては本がないという。。