Reposado
久々にシリコンバレーレストランの記事。


google maps
パロアルトでちょっといいレストラン(会食、パーティ)を予約しないとなーって時に役立つレストラン。 Fine Mexican Diningの名前の通り、洗練された高級志向のメキシコ料理が食べられる。 またレストランの雰囲気もよく、地元の人でいつも賑わっている。 混むので数日前のテーブル予約は必須です。
もちろん定番のナチョスやタコス、セビーチェも美味しくメインの肉料理も外れはない。ちょっと高いけどラムチョップがとても美味しい。
自分は飲まないからよくわからないけど地ビール、地ワインのラインナップが豊富。 また特にオススメは自家製マルガリータ

ハードウェアの速度をどう評価するか考える(1) ~クロック、OPS~
この記事の目的
現代ハードウェアの計算性能を評価する尺度であるメモリ律速の概念とルーフラインモデルについて理解を深めること。
対象読者はメモリバンド幅やOPSなどの概念があまりわかっていない人です。例えば本記事を通し、あるアルゴリズムが速度が十分に出ない時、それがハードウェアのどの性能(メモリか演算)に律速されてるかイメージできるようになるのが目標です。
思うままに書いていたら肝心のメモリの話まで行きませんでした。そのため前編はクロックや演算(OPS)についてです。

この図はTPUの論文に出てくるRoofline modelです。この図が意味するところを理解するのが本記事の最終目標となります。
ハードウェアの速度をどう評価すればいいか?
ベンチマークによる評価
ハードウェア速度の評価は昔から大きな問題でした。わかりやすい評価指標にある代表的なアルゴリズム数種類で性能をベンチマークするSPEC)などがありますが、ベンチマークの数値だけ見ても実際何故性能が出てるか紐解くのは難しいです。またベンダーの出しているメモリバンド幅や計算性能なども読み解けないかもしれません。ただSPECは同じアルゴリズムを異なるハード上で行うため、ある程度フェアな比較はできます。
CPUクロックによる評価
昔のハードウェア速度はcpuクロックで測れてました。というのもCPUは大体1クロックで一度の演算をするため、クロック速度から大体の性能を予測することができます。一方で並列演算などの要素が入ってくるとこの方法で性能を見積もるのは難しくなります。
またプログラムの計算時間を見積もる際には十分通用します。例えば競プロでは計算量がO(1e9)のプログラムであれば1GHz CPUで1秒で回ると概算できることを最初に習いますね。一般的に競プロのアルゴリズムはシリアル処理なのでこのような見積もりが当たります。(並列化速度はライブラリの出来なので競技性はないですね。。)
OPS、SIMDによる評価
しかし並列演算を行うと単純にクロック速度だけではハードウェアの性能を正確に評価できなくなります。
例えば近代CPUには並列演算(ベクトル演算とも)が実装されています。並列演算回路は多数の演算機(ALU)を並べ、N個のデータを受け同時に演算を行いN個の出力を出すというものです。
この並列化は全ての入力データに対し同じ計算を行うため(例えばベクトルに対し+5を行うなど)、並列化が可能になります。これはスパコン用語で言うとSIMD(single instruction Multiple Data)という名のデータ並列性であり、良く機械学習、グラフィックス、科学演算などで使われます。グラフィックスなどはこのように全てのピクセルに対し同じ計算(定数の足し算や掛け算)を行うためSIMDによって膨大な速度ブーストが得られます。身近な実例ですとnumpy arrayを使うと中では妖精さんがSIMD機能を使ってくれます。そのため生pythonより遥かに高速にベクトルや行列演算をしてくれます。
またGPUも大雑把に言うとSIMDプロセッサの延長線と理解することができます(GPUはSIMDに加えマルチスレッディング、マルチコア性能がCPUに対し大幅に加えられたヘテロジニアスマルチコアシステムですがGPUアーキテクチャに関してはそれはそれで本が一冊書けるのでそこまで今回は深く立ち入りません。)。
CPUとGPUのアーキテクチャ的な違い、SIMDやマルチスレッディングについて深堀りはCMU大の講義が詳しいです。
http://15418.courses.cs.cmu.edu/spring2017/home(15418.courses.cs.cmu.edu]
また日本語で詳しくSIMDや並列演算について知りたい人はこれとか読んでみて下さい。
https://kaityo256.github.io/sevendayshpc/day7/index.html(https://kaityo256.github.io/sevendayshpc/day7/index.htmlkaityo256.github.io]
A100チップのOPSを計算してみる
とにかく並列演算を持つハードウェアの演算性能は単純にSIMDのデータ数N, clock rate, 演算器コア数の掛け算で求めることができ、OPS(operations per second)といいます。
例えばnvidia GPUのOPsを計算して製品スペックと一致するか見てみましょう。
nVidia A100のスペックは以下です。
https://videocardz.com/newz/nvidia-announces-tesla-a100-specifications

FP32のOPSは
OPS = CUDAコア数 * GPUクロック * 2
で求められます。*2としているのはCUDAコアは一クロックで掛け算と足し算両方を実行できるため(MAC)、そのような回路は1クロックで2OPSの動作ができると慣例的に計算します。
そのため、
OPS = 6912 * 1.41GHz * 2 = 19.49TOPS(テラOPS)
とスペックの19.5TOPSの値が得られます。
同様にTensorCoreのOPSも計算する事も可能です。
ここによると)A100はTensorCoreを432個持ち、一クロックで16*32コの計算を扱えるとのことです。そのため
OPS = 16 * 32 * 432 * 1.41GHz * 2 = 623.7TOPS
とスペック状のBF16の624TOPSの値が得られることがわかります。TensorCoreの設計上16*32の演算をフルに扱えるのはBF16のみで、FP32となると演算器の数は半分となってしまいTOPSも半減します。一方でINT8では実効的に演算器の数を倍に増やしたかのように見せられるため、TOPSは倍増します。
Kaggle戦記~Kaggle Masterになるまでを振り返る~
https://www.kaggle.com/kyoshioka47
目的
この度約10ヶ月間Kaggleに参戦しCompetition Masterになり賞金も獲得できました。本記事では参戦したコンペ中の思考や得られた事を振り返り記録します。これからKaggleを始めMasterを目指す人の参考になればと思います。
また試しに昔登録したamazonアフィリエイトのリンクをいくつか貼ってみました。コーヒー代を寄贈する気持ちでクリック先で本を買ってもらえると嬉しいです。
バックグラウンド
自分は集積回路設計で博士取得後、機械学習アクセラレータの研究をしてました。そのうちにコンピュータービジョン技術自体に興味を持ち、論文などを独学で読漁ってました。Kaggle参戦に役立った本、論文などは最後にまとめます。
また仕事でも機械学習用データセットやタスクなど設計してました。 しかし"動けばいい"が優先されるタスクであり、精度が求められないのがつまらない点でもありました(そもそも精度指標も自分で設計してる。。)。そこでアルゴリズムをもっと詰めてモデルを設計してみたいというもやもやはずっとありました。
始まり
D社のカジュアル面談でkaggleについて聞いたのがkaggleを始めたきっかけだったと思います。提供されたデータセットを元に、一番良いモデルを作るという明快さとモデル設計をもっと深く追い先端技術も試したいという想いからkaggleに登録した記憶があります。要はなんか面白そうだからやってみるかー!くらいの気持ちでした(今もそんな感じですが)
ちょうどKaggle勝つ本が出た頃で、本のさを読みながらtitanicをやった後、あまり考えずにそのままLyftコンペに参戦しました。
Lyftコンペ

LiDARデータから3D物体検出を行うコンペでした。Kaggleで初のLiDARデータを使ったコンペだと思います。
ただデータセット構造がオリジナルで中々本丸のアルゴリズムまでたどり着かなかったです。 自分は参加したのが終了2週間前というのもあり、PointPillarsを動かそうとしているうちに終了しました。
結局ベースラインモデルをちょっと大きくし、TTAを足したものを提出して40位の銀でした。運良くメダルが取れ、モチベーションが以後のコンペに向けて高まったのはよかったです。
いきなりソロ銀が取れた背景として問題設定の難しさからコンペ自体過疎っていてプレイヤーが少なかったのが大きいと思います。
色々穴のあるコンペでしたが*1、ロボビジョン研究者としては一番リベンジしたいコンペです。
学んだこと
- Kaggleノートブックを使ったEDA、学習
- 銀上位以上とそれ以外との圧倒的な差。
Kaggleで強い人って?
- 銀上位以上とそれ以外との圧倒的な差について補足させてください。
Kaggleコンペでは公開notebookコピペでも(運が良ければ)メダルは取れます。だからメダル二枚でなれるExpertではその人が本当に分析者として優れているかはわからない、と言われてしまうのだと思います。
ただ コピペでは超えられない壁が銀上位あたりにある印象があります。
Bengaliコンペで自分は実感するのですが、この壁を超えるのに必要なことはホストが出した問題に対し、クリエイティブな解決策が提示できるかどうかだと思います。 この点がKaggleの"競技データサイエンス"的な面で一番おもしろいポイントであり、Kaggleディスり勢が理解していないポイントと感じます。 主観ですが、データサイエンスの難問に対し独自のアプローチを取れる人は業務(開発、研究問わず)で強いと思ってます。
なのでKagglerの実力を見るときには1) コンスタントに銀上位のパフォーマンスが出せているか、2) クリエイティブなソリューションで問題にアプローチしていたかを見ると強い人かどうかわかると思います。偉そうに書いておいて自分はまだ1)は達成できてませんが。。
PKUコンペ

Outrunner氏のsolutionより
2D画像から車の3D位置と姿勢を推定するというCV的にも先端内容のコンペ。
問題設定が面白く、コーディングもなかなか難しいとやりがいのあるコンペでした。 CenterNetを使い倒し大規模2D CNNの学習を詰めれたのはいい経験でした。
PKUコンペの特徴として3D位置推定を行う既存ライブラリはないため、モデルをほぼスクラッチ実装する必要がありました。 PKUコンペを通じて自分はいくつかの論文のスクラッチ実装を行った記憶があります。 様々なアイデアをインプリするうちに 駄目駄目だったコーディングがだんだんマシになっていくのを感じました。
コンペはoutrunner氏が大差をつけて優勝しました。
Outrunner氏のカメラキャリブレーションパラメータを使って3次元回転のaugumentationを行うソリューションはとても面白く、一見の価値あり。言われてみれば確かに!と思うのだがなかなか思いつかない簡潔で有効性の高いソリューションでした。
ただ自分はネットワーク設計が最後まで良くなく(FPNを上手く実装できず)、90位の銅でフィニッシュしました。
コンペ的には色々ありましたが*2、ギリギリ致命傷にはならず最後までコンペを楽しめました。
学んだこと
- コーディング力
DNNのパラメータ調教が上手くなった。
やみくもにチームを組まない
補足です。PKUコンペではあまり考えずに0サブのNoviceの方と組んだ後、連絡が取れなくなってしまうという自体が発生しました。笑 チーム組むときはそれなりに実績ある方かスコアをそれなりに出している方と組んだほうが良いと思います。あとTwitter上で日本人の方と知り合いになりチームを組むのは(人間性、言語面)からおすすめです。またLBで銀上位につけていると結構強い人からもマージリクエストがくるようになりました。
Bengali
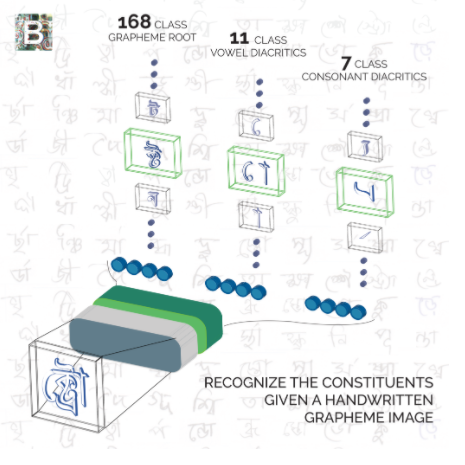
Shake Downの洗礼
Bengali文字認識を行うMNISTの延長線のようなコンペ(と当時は思ってました。) またこのコンペでは強いチームメイトと組むことができ、色々刺激を受けながら戦うことができ、とても楽しかったです。
そのため画像認識の技術を詰め込んで適当に学習させればいいや~という舐めた意識で(自分は)コンペに参戦していました。
結果としてコンペの趣旨を捉え違えていたので 49位から170位までShake Down してしまいました。

Shake Downの原因
ShakeDownの原因はコンペ説明文をよく読む・理解していないことでした。
なのでKaggleで勝ちたい、つまり運では難しい銀上位以上を目指したいならば、コンペに出る前にいくつか確認することがあります。 * 1) どのような機械学習の問題なのか?(画像、テーブル..) * 2) ホストが解きたい問題は何なのか? の二点だと思います。
例えばBengaliではベンガル文字はGrapheme, Vowel, Constantと3つの部首で構築されますが、未知なる部首の組み合わせにも対応できるような機械学習モデルを作れるか?というのがホストからの挑戦でした。
例えばBengaliでは3位のソリューションは文字がtrainに含まれていたか否かをarcfaceで判定後に未知クラスに強いモデルで判定する、1位は未知クラスはCycleGANでスタイル変換したあとに判定することで判別精度を向上させるなど特にIn-the-money圏内のチームではホスト課題にあったアプローチが多く勉強になりました。
ShakeDownを避けるために実践したこと
BengaliでShakeDownしたのはめちゃくちゃ悔しかったですし、このままKaggleをやっていても一生金は取れそうもなかったので、大きく反省し戦い方や準備の仕方を変えました。
まずホストが解きたい問題を読み取るためにコンペ説明はよく読み込む必要があると感じました。またホストがデータセットに関する論文を出していたら熟読するのが良いと思います。前述した二点目を解決するアイデアを実装できるか否かが銀上位にいけるか行けないかの分かれ道だと思います。(文章で書くと当たり前に感じますが、LBを上げることしか頭にない方も過去の(自分を含め)残念ながら多くこれを実行できている方は多くないとコンペ参加経験から感じました。自戒の意味も込めて厳し目に書いておきます。)
例えば自分は過去コンペの説明を読み込みホストの課題を理解し、上位陣がどのような具体策でその課題にタックルしたか、という視点で過去二年分くらいのコンペソリューション(上位陣のみですが)を読み漁ったのが良い勉強になりました。例えばクジラコンペやASPLOSはいい教材でした。あと強いKagglerのソリューションをまとめて読むのも勉強になります。(日本の画像系ではphalanxさんとか)
PANDA
チームアップ
Bengaliの反省後、参加したコンペでした。
このコンペではfamtaroさんやpotemanさんとつよつよなMasterと組むことができ、"勝ったな.."感はありました。
.@arutema47 さんが Master になるRTAに参加しもうした pic.twitter.com/vNaw1x2IgO
— ふぁむたろう (@fam_taro) 2020年7月5日
優勝
チームメイトではSlackで日々議論しながらモデル設計をし、特にコンペの最重要課題であるnoisy-labelに対応するかについて頻繁に議論しました。 結果的に実装したnoisy-label対策が大当たりし、まさかの優勝することができました。Goldは夢のまた夢だったので取れてかなり嬉しいです。
!?!?!? pic.twitter.com/PqygjM6oe8
— arutema47 (@arutema47) 2020年7月23日
チーム的には銀を維持して銅までshakeしなければいいな、というノリだったのでSlackでチームメイトが"1!"と送って来た時はかなり驚き、午前中は仕事になりませんでした。
優勝は出来すぎにしても、目的であったコンペ趣旨に対しオリジナル技術で対策を行いモデルを組めスコアを上げれた事はべんがりでの経験を上手く昇華することができたことに繋がり嬉しかったです。
ここでは技術的な面には触れませんが、具体的なソリューションは下記に記述してます。
また自分より遥かに優れた文才でfamtaroさんが参戦記を書いているのでそちらも御覧ください。
Winner's call
Kaggleの賞金受領手続きについて記述しておきます。 Kaggleでは賞金圏にはいるとホストへ報告書とモデル提出、そして電話会議でプレゼンするWinner's callという手続きが必要になります。
具体的な提出アイテムとして
- モデル学習、推論のスクリプト提出
- モデルについてのアプローチや考察を記述した報告書(20ページくらいのパワポ資料としてまとめ、自分はWInner's callのプレゼン資料として使いまわしました。)
の二点が必要です。両方Kaggleからテンプレートなどが支給はされますが、自己フォーマットでも筋が通っていれば問題ないです
またWinner's call自体はGoogleの会議ツールを使い組まれました。発表25分、質問30分の計1時間でした。 質問はDNNの学習パラメータ、augumentationといった技術的な話からどのような実験をして最終的なアプローチにたどり着いたか、試したが動かなかったアプローチとその考察などを聞かれました。学会のQ&Aの緩い感じをイメージしていただければと思います。お互い英語は母国語ではなかったので英語でそこまでボコボコにはされませんでした。
また賞金受領やWinner's callの手順はカレーちゃんさんのブログもとても参考になりました。(自分は個人で賞金受領したため、"W-8 BEN"をサイト上で記入しました。)
"Kaggleで賞金を獲得したら家族のために使う"と以前から宣言していたため、家族マターに有り難く使用します。笑 note.com
また本解放がMICAAI workshopへのinvite講演など学会ワークショップへ結びついたのもよかったです(こちらはfamtaroさんに投げてしまいすみません。。)
闇の小麦コンペ

闇が多すぎて正直ノーコメントです笑*3
Publicでは8位だったものの、Privateでは78/2245位までShakeDownしSilverとなりました(死)。Privateのbox特性が大きく変わってしまいそれに対応できなかったのが敗因でした。
何はともあれこのコンペを以てMasterへの昇格を"キメ"ました。やったぜ
結局小麦は10位から80位までshakeして銀でした。金がいいです..
— arutema47 (@arutema47) 2020年8月19日
何はともあれ目標のMasterになれてよかったです🙇 pic.twitter.com/ou4fbiPPHY
最後に勉強してよかった本、論文
Kaggleの参戦前に読んでおいてよかったと思う厳選書籍をいくつか紹介します。他にも機械学習系の本はたくさん買ってましたが全部売り、結局これらがのこりました。
Kaggle,機械学習の本
Kaggleで勝つデータ分析の技術

この本がなかったらKaggleのコンペ参戦まで行けていなかった気がします。
"Kaggleとは何か"から初心者用コンペのTitanic参加するまでの道のり、そして更にテーブルコンペで勝つためのテクニックが一冊にまとめられている良書です。
自分はテーブルコンペには出たことはありませんでしたが、評価指標の詳細解説や特徴量設計の章は参考になり業務でも活かせる方が多いと思います。 ただ内容は機械学習の初歩は理解していることが前提なのでこれ一冊で戦えるようになる、というわけではないです。初学者ですと下記の本一冊も同時に読んだほうがいいかもしれません。
Python機械学習プログラミング

回帰、SVM等の機械学習やデータ分析の基本を叩き込むのには良書です。会社のAI系部署の新人研修でも使われていました。 網羅している事柄も多く、最初の一冊にはかなりおすすめです。
第三版まで出てますが、ディープの内容が追加されているのが差分です。第一版でも十分勉強になります。
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

ディープラーニングを勉強するならダントツでこの本がオススメです。研究でも実務でも一番役に立ちました。G検定とか勉強してる場合じゃないですよ!
通称ゼロ作で日本発書籍ではダントツのクオリティを持ちます。
DNN、CNNの推論と学習を一からNumpyで順を追って実装する良書です。DNNの具体的な演算もイメージできるようになるので応用が効きやすく、今でもはじめの一冊としては最高だと思います。何度読み返したかわからない。。笑
NLPに興味あるならゼロ作2もオススメです。
PyTorchによる発展ディープラーニング

Pytorchで戦いたい方はこの一冊を写経するのがおすすめです。
画像認識、物体検出、GAN、自然言語処理とDNNの幅広い分野をカバーしている超良書です。
コードがとても丁寧かつ量も多く、これからpytorchを勉強しようとしている方には一番お勧めしたい本です。
Kaggleスタートブック

Kaggle勝本よりも丁寧に機械学習初心者向けにtitanicコンペについて解説をしてくれます。あまり機械学習やプログラミングの経験がない場合、この本から入りその後にkaggle勝本のステップアップするのが良いかもしれません。
個人的には機械学習プロフェッショナルシリーズ(深層学習)などは式が多くあまり技術がイメージできず、直接論文読んだほうがわかりやすかったです。
論文など
駆け出しのころに勉強したCourseraのNg先生の基本コースは参考になりました。ゼロ作を読んでも同じところをカバーできる気がします。
画像認識系の論文はそれなりに読んでいました。例えばPhalanxさんのkaggle_tipsに読んでおくと良い論文のまとめがあります。 github.com
今後の抱負
Masterになれたものの、まだまだ実力不足を実感します。今後もロボットビジョンに近いコンペに出場しながら着々と実力を付けていきたいです。
対戦よろしくおねがいします!
RNNからTransformerまでの歴史を辿る ~DNNを使ったNLPを浅く広く勉強~
 Seq2seqからBERTまでのNLPモデルの歴史をざっとまとめる。
Seq2seqからBERTまでのNLPモデルの歴史をざっとまとめる。
DNNは知ってるけどTransformerってなんだかわからない、って人におすすめです。
Abst.
画像認識にもTransformerが使われることが多く、DeepRLやGPT-3といったNLPモデルも身近になってきています。"Attention is 何?"と言えなくなってきたので勉強しました。
Feedforward NetworksからSeq2Seq, Attention機構からTransformer登場、そしてBERT GPTといった最新モデルまでの流れを広く浅く記述する予定。
またKaggle NLPコンペの上位解法から利用例を探る。
Tl;DR
TransformerはSelf-Attentionという機構でデータ内の時系列的特徴を抽出でき、従来のRNNを始めとするNNに対して 100倍以上計算効率が優れる。
この優れた計算効率を活用し、近年は 莫大なデータ量と計算量で巨大なモデルを学習し、NLPモデルの精度を凄まじい勢いで改善している。
その過程で出てきたモデルがGPT-3やDeep-RLなのだと思う。
- Abst.
- Tl;DR
- フィードフォワード型NNの課題
- Seq2Seqの登場と課題
- Attentionとは
- Transformerとは
- Generative Pre-training (GPT-1)
- Bidirectional Encoder Representations from Transformers (BERT)
- Computer Visionへの応用~Vision Transformer(ViT)~
- KaggleのNLPコンペ
- Next Step
- 参考文書
フィードフォワード型NNの課題
CNN等はエンコーダとしては優れているものの、時系列情報を埋め込めないため、単語の並びは無視されてしまう。そのため翻訳など自然言語タスクでは使用できないのが課題。
例えば画像を左右反転してもCNNは犬の画像を犬と理解してくれるが、左に犬がいたか右に犬がいたかモデルは理解する術を持たない。
ちなみにDetectionでも統合的な位置関係を"理解"しているわけではない(反応したboxに応じてメタ的に情報を出せるが)。
ネットワーク自体は空間的にフィルタを適応しているだけで左右に二匹いたというコンテクストはなく、画像の意味理解を始め文章の翻訳や意味理解は難しい。

自然言語理解(NLP)では周囲のデータ(word)に対する重み付を計算する機構が必要で例えば文章理解にはeatは周囲のfoodを表すwordと高い重みをもたせたい。
この役割を果たすのがAttention であり、CV用DNNにはなかった機構である。
従来のCVでもこのような画像中の”意味理解”を果たすために、CNN+RNNを用いてキャプションを作成している。 RNNはリカレント(循環性)を持っており、単語間の特徴や単語の入力順までも含めて特徴量を抽出することができる。 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention。
Seq2Seqの登場と課題

2014年に提案された技術であり、時系列を加味したオートエンコーダのようなイメージ。
例えばエンコーダは文章を固定長のcontext vectorに変換し、デコーダはcontext vectorを別ドメイン(中国語)の文章に変換する。
NN自体のモジュールとしてRNN, LSTM, GatedRNNなどが使われるが本記事では深追いはしない。 過去と現在といった時系列のデータを上手く扱えるようにしたNNモジュールと思えば良い。
ゼロから作るディープラーニング2に丁寧に原理や実装方法が載っているので興味のある人は読んでみて下さい。
Seq2SeqやRNNの課題:
RNNは順次にデータを入力し処理するが長い文章を入力すると最初の方の文章について”忘れてしまい”、文章全体の理解は難しい。
- Context Vecは単一の固定長ベクトルであり、保持できる情報量は限りあり
- これを長くすると今度は短文の理解が難しくなるというトレードオフ
隠れ層で"前状態"の特徴も伝搬させていくものの、限度がやはりあり例えばブログ記事全て(1000単語)などを理解させるのは困難。
Attentionとは

Self-Attention Mechanisms in Natural Language Processing | by Alibaba Cloud | Mediumより

Attentionは人間の目の仕組み(Visual Attention)からインスパイアされたNNの機構である。
考え方:
目はあるパーツを見ている時に共に周囲の関連する画像部位を"低解像度"で見ることで、画像全体の理解を図る。
この"低解像度"でみることはある重みで周辺データを加算することと同義であり、この仕組をDNNに取り入れた。
例えば画像の柴犬の耳(黄色箱)を見ているとき、人間の目は周囲の耳や鼻も低解像度で見ており、犬全体のコンテクストも理解している。
Attention(初期)の実装
Attention初出:Neural Machine Translation by Jointly Learning to Align and Translate

RNNの各隠れ層の状態からContext Vectorに作用させるショートカットを作成している。
- AttentionLayerがEncoderの各隠れ層から単純に全結合で情報を取り、Context Vecとさせる。
- RNNのエンコーダ隠れ層Ht全てを利用し、ContextVec.を入力に依存した行列にする
そうすることで文章全体から特徴量を効率よく抽出可能。
デコーダはデコーダRNN出力+EncHtの特徴量両方を使い出力計算する。
Transformerとは
初出:Google, Attention is All you Need NLPで間違いなく最も有名な論文で初学者でも読みやすかった。
Googleが出すgame-changingな論文は(EfficientNetとか)とても読みやすい。 奇を衒わなくてもトップ学会に通るポテンシャルがあるからか。
従来モデル(seq2seqとRNN全般)の課題

RNN系NNモジュールは前ステートの状態を受け取らないと計算を始められない。
すると計算の並列化は本質的に難しく、計算が遅いのが最もクリティカルな課題。 (要はGPU計算効率が低く、たくさんのデータで学習できない)
例えばn入力=(x0, x1, x2, x3, .. xn)あったとき、RNNが隠れ層=(h0, h1, h2, h3..hn)を計算するためにはnステップが必要である上に例えばh2はh0とh1に依存し計算を並列化する事ができない。単純に言うと 計算時間がO(n) となってしまう。
バックプロパゲーションを間で切るというテクニック等で並列化・高速化もなされてきたが、シーケンスが長いと情報量は落ちてしまうし本質的な解決にはなっていなかった。
革命はなぜ起こったか?

私にいい考えがある
RNNをベースとした構造からTransformerではAttention(正確にはSelf-Attention)をベースとした構造に進化した。

Self-Attentionは入力ベクトルのみから出力を並列計算で導出可能で計算依存性がなく、GPU計算に向く。 十分に並列ハードウェアが使用可能ならば 計算時間はO(1) である。
またそもそもSelf-AttentionはRNN、CNNセルよりも計算する要素が少なく高速である。 n=10, d=512のタスクと考えると Self-Attentionの計算量は50倍少ない。

実際Transformerの論文ではRNNベースの手法と同等精度に達するために必要な演算量は 100-1000倍少ない と報告している(そして計算時間は更に高速)。
このようなAttentionベースの構造、 Transformer をGoogleは提案し、NLP精度に革命を起こした。
DNNはそもそもデータを学習時に喰わせれば喰わせるほど精度を向上できる性質を持つ事を思い出したい。
Transformerというリカーレントな特性を持ちつつ並列化に向いたモジュールを提案することで、NLPモデルにより多くのデータで学習可能となりモデル精度が爆発的に向上したと自分は思ってます。
Transformerブロック図

まずはアーキテクチャとしての動作を見てみる

アーキテクチャ全体の概要はGPT-1論文の図がわかりやすい。
イメージとしてN入力に対しTransformerEncoderをそれぞれ計算し、N個の特徴量を抽出という点はSeq2SeqやRNNと変わらない。
しかしTransformerEncoderは依存関係がなく、GPUでN並列で計算が可能である点が革新的であった。N個のコアがあれば1回のステップでTransformerは計算が終了するため、RNNよりN倍計算が早い。
そしてデコーダにも前述した特徴量を入力し、エンコーダとほぼ同等に並列で高速計算が可能である。
Transformerブロックとしての動作
論文を見るに非常に単純で基本的にはSelfAttention→(ResidueとAdd)→FC→(ResidueとAdd)しているだけ。
PytorchのTransformerEncoderLayerソースコードを見てみよう。 https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/transformer.py

forwardはとてもシンプル。 それだけself_attentionが強力ということだろう。
ちなみに元論文ではこのエンコーダを6回Stackしている。
Self-Attentionとは

Transformerの要は間違いなくSelf-Attentionである。
self-attentionではあるベクトルX=(x0, x1, x2, x3, xn)が与えられた時、Xに対しまずクエリとキーを計算する。
そしてアテンションαをクエリとキーの内積結果から算出する。このクエリとキーの演算によってXと重みクエリとキーの類似度を計算している。
そして最後にバリューを計算し、アテンションの結果を重み付けした値を得る
TransformerにおけるSelf-Attentionは Scaled Dot-Product Attention という方式を利用。(他にもたくさん計算方法はあるが、現状はこのAttentionが寡占しているよう。)
計算はシンプルで以下である:

計算のフロー: queryとkeyに対し内積をとり正規化後に非線形化(softmax)し、最後にvalueと内積を取る。
復習: 式をみてもイメージが沸かない人は内積の意味を思い出そう。内積はベクトル同士の類似度を取ること。
考え方: まず各keyそれぞれにおいてQueryのどこと類似性が高いか計算する。 Attentionのそもそもの考え方は入力(key)と類似度が高いデータを取り出したい、というものだ。 特にCNNのようにフィルタで計算し抽出するわけではなく、あくまで自己のデータ性質に注目し出力を作る。
Q K と計算した類似度の高い(注目するべき)領域をVと更に内積を取ることでデータを抽出しているイメージ。
このようにkey,query, valueが同一データから来ているため"self"-attentionと呼ぶ。 こんなにシンプルな仕組みが強力の結果を生むというのは驚きだ。
(うーん、よくわからん!となったら最初の柴犬の例を思い出してベクトル内積を復習してみると良いかも。)
重要な事はGPU的には内積演算は非常に効率よく処理することができ、Transformerの全てのブロックはGPU-friendlyであるという点だ。
MultiHeadAttention

実際にTransformerで使われるのはSelf-attentionを発展させたMulti-head-attentionである。 Self-Attentionを複雑にして表現力を増したものと考えると良い。
Self-Attentionと違い、Multi-head-attentionでは学習する重みが出てくる。
- 考え方:
V,K,Q全てを全結合層でh次元に変換し、h個のAttention機構に入力する。
そしてh次元の出力をconcatし、全結合で元の次元に戻す。
h個に次元を拡張するため、multi-headと呼んでいると思う。
- なぜこんな事を?:
" Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions "
感覚的にはこちらの方が表現力が増える、という事を元論文では記述しており元論文ではh=8を採用している。
Generative Pre-training (GPT-1)
OpenAI, "Improving Language Understanding by Generative Pre-Training"
 アーキテクチャ的にはTransformerを活用しているが、Transformerエンコーダのみの構造になりDecoderはなくなった。
アーキテクチャ的にはTransformerを活用しているが、Transformerエンコーダのみの構造になりDecoderはなくなった。
どこがブレイクスルー?
学習方法にGenerative Pretraining、一種のsemi-supervised learningを活用することで大幅な精度向上が可能な事を示したのがブレイクスルーであった。Generative Pretrainingは後続のGoogle BERTといった研究にも大きなインパクトを与えた。
文章生成のリアルさが凄く、GPT-3では人間を騙せるレベルになり話題になった。
学習は大量のデータを活用するゆえに長いものの、一度Transformerをpretrainしてしまえばfine-tuningで様々なタスクに転用可能であることを示した。
Generative Pretrainingって?
DNNは大量のデータを食わせることで精度を増すが、大量のラベル付けデータを用意するのは難しい。
しかし自然言語ならば大量のラベルなしだが人間が記述した良質なデータは手に入る(Wikipediaなどを見てみよう)。
例えばこのような文章を収集したとする。
吾輩は猫である
そこで収集した文章にわざと穴あきを作り、その穴あきに何が入るかモデルを当てさせモデルを学習する。
吾輩は○である
このような学習方法(教師なし学習)により、文章データさえあれば 学習データをほぼ無尽蔵に生成できる 。
この手法をgenerative pre-trainingと呼ぶ。

計算効率を向上させたTransformerと無尽蔵の学習データを生成するGenerative Pre-trainingによりNLPモデル精度は凄まじい勢いで2018年から伸び始めた。。

GPTでは事前学習したTransformer自体はそのままに変えず、タスクによって入力方法や大枠のアーキテクチャを変更することで使い回す。
GPTは 教師なし学習でTransformerを学習(Pretrain)し、最後に貴重なラベル有りタスクに特化したデータで ファインチューニング するという現代NLPモデル学習の基礎を確立した。
例えば、大体KaggleのNLPコンペをやる時はGoogleが公開しているPretrained-BERTモデルをダウンロードし、タスクに応じてアーキテクチャを組むという流れだと思う。
Karpathy兄貴のMinGPT
ミニマルなGPTのコードが公開された。これを読むのがわかりやすいかもしれない。
GPT-1 vs GPT-3
アニキのREADMEによるとGPT-1とGPT-3の差は
GPT-3: 96 layers, 96 heads, with d_model of 12,288 (175B parameters).
GPT-1-like: 12 layers, 12 heads, d_model 768 (125M)
と1000倍ほどモデルサイズが異なる点であると思う。もちろん学習時間も1000倍かかる..
Bidirectional Encoder Representations from Transformers (BERT)
Google, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
神論文2。みんなで読もう。
Transformerの課題

サイバトロン戦士、トランスフォーム!出動!!
Transformerは強力で高速なものの、時系列情報はあまり強く学習できない。
文章単体ならば強力にできるが、例えば数千単語に及ぶ文章の意味理解は難しい。
Bi-Directional Transformers


- Transformerを双方向にしたものを提案。
- Attention機構のようにエンコーダ隠れ層全てを使っている
- Seq2SeqのDecoder機構は使わずに実装。
GPT-1で提案されたpretrainingを適応し、更に精度向上。
名前の由来。。
ELMoへのリスペクトからか、NLPはセサミストリートのキャラ名をもじったモデルが多い笑
Computer Visionへの応用~Vision Transformer(ViT)~
Vision Transformer 原題:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scaleという研究で画像認識にTransformerを使いSota CNNと同等の精度を達成したことが話題になりました。
Vision Transformerの論文では画像を16x16の切れ端にcropし、それを"単語"として見てTransformerに入力します。 そこから論文のAn Image is Worth 16x16 Wordsというネーミングが来ています。画像も単語のように扱えるよ!というNLP→CVに技術が浸透した面白い例ですね。
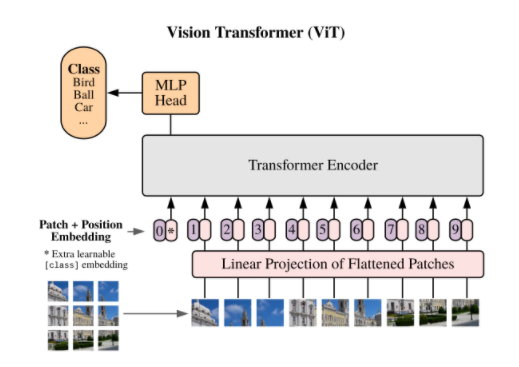
Transformerのアーキテクチャは変えずに(ネットワーク自体はBERTとほぼ同等)、画像の入力方法を工夫することでCNNと同等のImageNet認識精度を達成するネットワークを実現したことから大きく話題になりました。

ViTは信号処理的には16x16のstride16 convolutionを初段で噛ませ、次段以降は全てのパッチ情報を加味した特徴量抽出になっている。初段はCNNに似ているが、次段以降は全く違う処理という議論。https://t.co/vj5N1KpxgO
— arutema47 (@arutema47) 2020年10月13日
ViTの初段はConvolutionと同等の処理をしますが、次段以降は全てのImagePatchの情報を組み合わせ特徴量抽出を行うので従来CNNとは動作が大幅に異なります。 そのため今後もCNNでは到達できなかった精度やタスクを実現できる可能性はあり、今後の発展から目が話せません。
[追記]
CIFAR-10でViTを学習させてみました。
やはり巨大なデータセットでpretrainしないと性能は出ないようです(resnet18なら90%出るところ、ViTをスクラッチから学習すると80%程度しか出ない)。 GoogleのViTモデルで転移学習した場合、99%精度出ることが確認されてます。
KaggleのNLPコンペ

いきなりソリューション読んでもちんぷんかんぷんなのだ。
小学生並の感想ですが、NLPはfeatureエンジニアリングや前処理、後処理エンジニアリングが効く部分が多く、Tableコンペ強勢に人気ありGMが台頭するのかなと思ったり。
GMが多いコンペはいいコンペ。
Google Q&A
ぐちおさんのブログが素晴らしいので読んで下さい:huggingface:
FacebookのRoBERTa、BARTなどが精度ー計算量のバランスが良く、たくさん使用されている
https://www.kaggle.com/c/google-quest-challenge/discussion/130047
huggingfaceという会社が出しているTransformer, BERTはTockenizerといったNLP前処理関数が使いやすく幅広い参加者に使われているみたい。
Tweetコンペ
これもぐちおさんのブログがとてもわかりやすいのでry
とてもわかりやすく闇と光:huggingface:がまとまっていました。
上位解法を読むとデータ前処理、ラベル処理に芸術が隠されてそう。 (アノテーションずれしたデータを渡すのは正直どうかと思いますが)
一位解法

どうStackingしてるんだろう笑 Transformerの特徴量を1x1 CNNに渡し分類器を構成しているんだろうか
Jigsaw
読んでない。
Next Step
いきなりBERTに手を出してもろくなことにならなそうなのでゼロ作2を元にSeq2Seqを実装し、Transformer実装まで行きたいと思います。
参考文書
【壁の向こうを見通すNLoSセンシングを野外で実現】Seeing Around Street Corners: Non-Line-of-Sight Detection and Tracking In-the-Wild Using Doppler Radar
ハイライト

壁などの裏の死角物体のセンシングを実現。例えば自動運転中にも壁の裏の歩行者などを早期発見できる技術に応用可能。
CVPR 2020
著者グループはNLoSセンシングの大家であるFelix HeideおよびMercedesBenz, Princeton大学等。
結果
 結果の図を見るのが一番わかり易い。
野外において壁越しにいる自転車、人物(黄色の点群)を検出できているのがわかる。
結果の図を見るのが一番わかり易い。
野外において壁越しにいる自転車、人物(黄色の点群)を検出できているのがわかる。
背景と従来の課題

NLoSは壁などで光を反射させることで、センサの直線状にない物体のセンシングを行う手法である。 これを応用することで壁の裏の物体をも見通す事ができる。
壁の裏側も見通せるNLoSセンシングは何年も活発に研究されていたが、それは主に非常に強いレーザ光を使用したものであった。 例えばCVPR2019のベストペーパーはレーザ光NLoSの画像復元に関する研究。
一方でこれらの光学NLoS系の研究は実験室内の環境では確かにセンシングに成功していたが、外乱に弱いため野外でのセンシングに報告した例はなかった。
提案アプローチ

 また論文の貢献としてミリ波NLoSの基本的な原理およびNLoS物体の速度もセンシングできる理論をまとめたのが貢献である。
式的には普通のNLoSとあまり変わらず、速度も確かに延長したら導出できそう。
また論文の貢献としてミリ波NLoSの基本的な原理およびNLoS物体の速度もセンシングできる理論をまとめたのが貢献である。
式的には普通のNLoSとあまり変わらず、速度も確かに延長したら導出できそう。
 物体の反射特性なども定式化されているがBRDFなどわかってないので読み解けない。。要勉強
物体の反射特性なども定式化されているがBRDFなどわかってないので読み解けない。。要勉強
NLoS物体の検出
 野外では反射・非反射する表面があるので、ミリ波レーダのスキャン結果のどの部分が実際にNLoSセンシングした部分か当てるのは難しいタスク(だと思うんだけどあまり論文では触れられていなかった)
野外では反射・非反射する表面があるので、ミリ波レーダのスキャン結果のどの部分が実際にNLoSセンシングした部分か当てるのは難しいタスク(だと思うんだけどあまり論文では触れられていなかった)
論文で用いているレーダでは壁等から一次反射(first-bounce、図中のW点で直接跳ね返った結果)とW点の壁反射し、更に物体で拡散した電波が再度W点で壁反射し筐体に戻ってきた電波をthird-bounceと呼んでいる。 ある面積以上の平面を検出し、更にその奥に点群が検出できている場合それをNLoS検出結果としてマークしているとのこと。
結構単純な方法でthird-bounceデータを検出できるのは驚き。。野外には平面等は多く見られるので誤検知とか多くないのか気になった。
3D物体検出
 ミリ波レーダベースの物体検出手法も提案されているけど、普通のBEV投影ネットワークに見えるためあまり新規性は感じない。
ミリ波レーダベースの物体検出手法も提案されているけど、普通のBEV投影ネットワークに見えるためあまり新規性は感じない。
nVidia 新GPU A100についての情報まとめ

nVidiaの新データセンター用GPU、A100がリリースされました。
このチップをベースとしてコンシューマー用GPU(RTX3xxx)もリリースされるのでしょう。
備忘録的にどのような新機能があるのかまとめてみました。 筆者の使用用途上AI性能にフォーカスしたものになります。またGPUは専門じゃないので間違いが合ってもあしからず。
ソース: NVIDIA Ampere Architecture In-Depth
GPUアーキテクチャについてはスタンフォード講義のCS348がわかりやすいです。
またCMUのパラレルコンピューティングの授業もGPUについてわかりやすく説明しています。
TL;DR
7nm世代に移行することでベース性能、キャッシュ性能が大幅Up
TensorCoreの改良と新データ構造TF32の導入、スパース演算機能によりV100に対し最大20x高速化
GPUのバーチャルインスタンス化機能を実現し、ユーザ間で単一GPUを効果的にシェアできるように。
A100はV100と同等のバーチャルGPUを7ユーザに同時に提供できると書いてある(気がする)。本当だとしたらかなり凄く、一番のキーフィーチャなんじゃないか。しかし私はクラウド人材じゃないのでよくわかりましぇん。
ハードウェア面
世界最大の7nmチップ
[P100, V100, A100]

まずはハードウェアの進化から見てましょう。
V100は12nmだったのが7nm世代に移行しました。 集積度もアップしており、GPUコア(SM)が20%ほど増加してます。
L2がV100の6MBから40MBに増えてるけどこれマジ?本当だとするとカーネルによっては演算が相当早くなりそうです。
一方でV100に対し最大クロックが下がっているあたりに設計者の苦労を感じます。
SMアーキテクチャ的には大きな変更はない。ただTensorCore(AI演算用専用回路)に大幅な機能追加が行われていて
7nmの設計経験はないんですが、この規模のチップを作ると歩留まりはかなり低いんじゃないか(毎回DS GPUみて思うけど)。多少歩留まりが悪くても圧倒的価格と性能(付加価値)でカバーできるのがNvidiaの強みであり他社が追従できない理由ですね。。
SM自体の仕様にはあまり変化ないですね。
TensorCoreの進化

nVidiaもオレオレFloating PointであるTensorFloat32という形式を提案してきました。 略してTF32と紛らわしい名前です。
このようなオレオレFloatingPoint導入のメリットは少ないbit表現でDL学習を実現できることです。
例えばSingleFloatの半分のbit数で同じモデルを学習すると
- メモリ使用量を半分に
- メモリ通信時間を半分以下に
- 演算も大幅に高速化
することができます。特にHPCではメモリ通信時間を減らすのが難しく、このようなデータ表現変更で2倍以上の高速化が達成できるのは画期的です。(HBM2の速度はここ数年全然変わっておらず次規格もまだ採用されていないですね)
TF32の仕様を見てみましょう。

FP16形式よりもexponentが3bit多く、ほぼ表現レンジは通常のFP32と同等なのが特徴です。FP16にそのまま3bit付け足した19bitの実装になっており、中途半端感は強いです。
Googleも同様のオレオレFloatingPointをTPUに実装していました(BrainFloat16)。 BF16はExponentを拡張する代わりにMantissaを削っていたのと対象的に、NvidiaはMantissaを重要視していますね。学習ではほぼExponentが効いている印象だったのでこのような実装にしたのは不思議です。
このようなオレオレFloatingPoint導入のデメリットは専用のカーネル(CuDNN的な)を書く必要があり、その最適化がかなり大変なことです。
ベンチマーク

TensorCore自体の演算性能が向上しているのでBERT学習が高速化しています。ベンチマークがBERTな辺りNLPの勢いを感じる。。

FP32で学習するのに対し、TF32で学習することでTensorCore+メモリ通信量を削減することができV100に対し7xの速度向上を達成しています。すげえ。
Sparcity
To be continued..
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving

密、かつ高精度な点群をステレオカメラによって得る研究。Depth prediction Networkの提案により高精度な点群の生成に成功している。
従来のステレオカメラは深度情報(カメラからの距離)のみしか得られなかったが、この研究では3D点群(つまりX,Y,Z座標)を獲得する。 高密度、高精度な3D点群をステレオカメラで得るメリットは: 1) LiDARベースの3D物体検出技術がステレオカメラに適応可能になる。 2) LiDARの高密度化に使える。
( 黄色のとてもスパースな点群がLiDARで実際に観測した点群。
赤、紫が従来のステレオカメラベースの点群である一方、本技術の点群は青。驚くべきことに高精度+高密度!
黄色のとてもスパースな点群がLiDARで実際に観測した点群。
赤、紫が従来のステレオカメラベースの点群である一方、本技術の点群は青。驚くべきことに高精度+高密度!
というかLIDARより密度が高いのでかなりブレークスルー。 LiDARで点群密度を上げるのはかなり大変で機器のコストもかなり上がる(数十倍とか)。
LiDARを使わない3D物体検出技術としてはかなり面白い技術で色々派生が出てきそう。(Psuedo-LiDAR++など)
CVPR 2019.
背景と従来の課題

自動運転には3D物体検出の精度が非常に重要である。 車の位置を3D binding boxで囲み、3D座標上でその位置を認識する必要がある。
一方でこのようなタスクではLiDARベースでは精度が高かったが、ステレオやモノラルカメラを使ったネットワークの精度は低かった。 具体的にはLiDARではIoU70%で70%程度の認識精度があるのに対し、ステレオ画像ではその精度はたったの10%程度と大きな差があった。
従来Deep+ステレオカメラの技術では視差マップ(Disparity Map)を学習するのが主なタスクであった。するとカメラからの距離Dは学習できるが、3D情報は得られない。そのため物体検出精度ではLiDARに劣っていた。
提案
この論文の提案は非常にシンプルである:
ステレオ画像から点群データ(psuedo-LiDAR)を直接出力するようにDeep Prediction Networkを学習する事で、LiDARと同様の3D物体検出ネットワークを適応できるようにする
だけである。本当にこれしか論文中でやっていない。(解析はちゃんと行っているが)
今までステレオカメラでは(長距離の)点群マップを得るのは難しいと考えられてきたが、そこのギャップを超えたのがこの論文である。実装自体はシンプルで、意外と”誰も気づいていなかったことをやってのけた”論文という印象。
従来はステレオ距離画像は(R,G,B,D)という表現で出力しており3D物体検出を行おうとしていた。一方で自動運転のような幅広い空間では奥行きをチャネルとして表現するのは難しく、隣接データの関連付けをうまく行うことは難しかった。
このようなデータ表現ではなく、ステレオカメラで点群(X,Y,Zデータ)を表現するようにprediction networkを学習することが可能であること、そしてそれが高精度に可能であることを示したのがこの論文の発見である。
驚くべきことにステレオ画像から推定した距離データの精度は非常に高く、ほぼLiDAR検出結果とオーバーラップしている。 そのため精度向上が得られたことは納得の行く結果だと思う。それでも精度は40%程度とLiDARに対し倍以上の差がまだ残っている。
関連論文(2020/6/18追記)

同著者による発展研究であるPsuedoLiDAR++ ICLR2020は疎なLiDARスキャン+ステレオカメラのデータを合体させることで密かつ正確な点群の生成に成功しています。
疎なLiDARであれば価格も安いのでスジの良い研究ですね。今後も要ウォッチです。