2021年面白かった本
実は三体とメダリストを布教する記事なんですが、オマケで今年面白かった技術書もまとめました。
技術書(順不同)
ディープラーニング学習する機械
")
ディープラーニングの歴史は耳タコだが、過去のAIブームからずっとニューラルネットを牽引している当事者が記述した貴重な本。
Brag-LuCunのあだ名通り随所に入る自慢話や悪口が軽快で面白いw
量子コンピュータの進歩と展望

量子コンピュータの基礎、応用、そしてこれからについてコンピュータ・サイエンス目線でスタンフォード大教授がまとめた本。
アメリカの本流としての量子コンピュータ研究がどのように向かっているかわかってとても良かった。
また一章に書いてある半導体発展の歴史も非常に面白い(ミーティングでよく言っていた)
研究者の仕事術

PIとしての時間管理術、プロジェクト管理術を書いた貴重な一枚。色々なビジネス書のエッセンスを凝縮しPI向けに書き直してくれているのが良い。
研究者に限らずエンジニアやフリーランスで一旗あげようとしている方ならば参考になることが多いと思う。
狭い世界でまずは世界一になれ
クオリティの高い成果の20%があなたの評価の80%を決める20/80の法則
など金言が多い。
科研費獲得の方法とコツ

科研費って何?からPI始めた自分にとって本書は大助かり。
RISC-V原典

RISC-Vの概要、利点から命令セットまで短くまとまっている。今更授業用に読んだけど面白かった。
ちなみに英語版は無料で読める。
Pythonではじめる数理最適化

数理最適化とはなんぞやから実務的データへの最適化の適応をいくつかのケース(クラス分けから割引クーポンの配分等)に分けて紹介しており実践的な一冊だった。
数式も多すぎず初学者向けなので、引き出しを増やしたい人に取っ掛かりとして読む一冊として良いと思う。
Reinforcement Learning 2nd edition
http://www.incompleteideas.net/book/RLbook2020.pdf
無料で内容が公開されており、強化学習の初歩から理論をわかりやすく記述している。
来年ゼロから作るDeepLearning④強化学習編が発売され似た範囲をカバーしてるのでそちらを読んでもよいかも。
小説
三体

久しぶりに時間を忘れて読んだ小説。オバマ大統領がファンであることを公言したことで話題になった中国発のSF小説。
翻訳者もSFの重鎮で非常にスムーズに訳されておりとても読みやすい。
第3部まであり、1部も面白いのですが2部から加速度的に面白くなってくる。ここまで面白い本には中々出会えそうにもないのが残念。
No Rules
 世界一「自由」な会社、NETFLIX (日本経済新聞出版)")
Netflixの社風について書いた本。
かなりぶっ飛んでおり真似できる気はしないが、何故この会社が急成長を遂げられたか垣間見れて面白い。
漫画
メダリスト
 (アフタヌーンコミックス)")

今年イチの漫画。
1巻はKindle版無料なのでまずは読んでみよう。
主人公いのりの成長は激アツですね。。個人的には3月のライオン以来の衝撃で5巻が楽しみ。
ラーメン再遊記
 (ビッグコミックス)")

【画像】ラーメンハゲ、ガキから正式にラーメンハゲ呼ばわりされる : チャーシュー速報
ラーメン発見伝を読んでいれば楽しめる、ネットで有名なラーメンハゲが主人公となったスピンオフ。
枯れたおっさんが放浪しているだけなんだけどなぜだかやたらと面白い。
クソコンペオブザイヤー2021
よくぞこの記事に来てくれた。 褒美としてクソコンペに参加する権利をやろう

本記事について
クソコンペオブザイヤー2021(KCY2021)へようこそ!
どうも、クソコンペ愛好家のarutema47です。
本記事はKaggleアドベントカレンダー(裏)の12日目の記事となります。
よくKaggleが(仕事の)役に立たないと言われる要因として
- データセットがキレイすぎて非現実的
- 実際に仕事ではそのようなキレイなデータセットは手に入らない
- 評価指標の設計こそデータサイエンティストの仕事として重要
という意見があり、ある程度的を得ていると思います。
一方でKaggleや他コンペサイトも常時キレイなデータセットかつ考え抜いた評価指標を提供しているわけではありません。評価指標のバグは日常茶飯事ですし、データのアノテーションバグなどもよくあります。ただこれらのバグに対しても指摘をすればすぐに対応してくれ、コンペに大きな支障があることは少ないです。
しかし明らかに狂ったデータセットやタスク設計のまま、最後までコンペが走ってしまうことが年に何度かあり、そのようなコンペはクソコンペの名を(主にTwitterで)冠します。これらのコンペにコミットしてしまうと中々辛いものがあるのですが、(良コンペからは決して学べない)反面教師として学べる事項が多いと思っています。
そのため本記事はクソコンペから反面教師として学びを得ることを主たる目的とし、特定ホストを中傷する意図はありません(炎上気味なタイトル付けといてなんですが)。またクソコンペの判断基準は著者独自のものです。もし他に取り上げたいコンペがありましたら、是非別記事を書いてみてください!
そして月刊Kaggleは役に立たないといった意見で"タスク設計やデータがキレイすぎる"と聞いた時はこのようなクソコンペも過去にったことをそっと思い出してください:angelface:
クソコンペを考える
KCY2021のノミネート前に著者が考えるクソコンペの要因を挙げます。端的にクソコンペとなりえる要因(以後クソ要因と略)は大きく4つほどあると思っており、それぞれブレークダウンしてみます。
クソ要因
- A データセットの品質が低く、コンペに重大な支障がある
- B タスク設計が悪い(今の技術では解くのが困難、評価指標が良くない)
- C 致命的なリークがある
- Dタスク設計に面白みがない(参加者目線ですが)
Aはまさに一番学びのあるクソ要因であり、本記事でも積極的に取り上げたいと思います。データセットの品質というと例えばラベルエラーがまず挙がります。後述するようにラベリングエラーが大きすぎるとモデル精度を正常に測ることができなくなってしまい、コンペが成り立ちません。
Bはタスク設計が難しすぎる・現在の技術では解くのが困難なため結果運ゲーとなってしまうコンペを指します。例えば6ヶ月後の株式を予測するコンペなどはタスク設計が難しすぎ、運ゲーとなってしまい参加者としてあまり面白みはありません(e.g. Jane Street Market Prediction、Two Sigma: Using News to Predict Stock Movements)。一方で同じ金融タスクでも短期間のボラリティ予測とタスク設計を工夫したOptiver Realized Volatility Predictionは色々ありましたが最終的には比較的良コンペだったのではないかと思っています(Time-series APIを使用しなかったためリークはありましたが。。)。
Cは学習データと同様のデータが評価データに混入してしまう"リーク(Leakage)"と呼ばれる現象です。これが起きてしまうとモデル自体よりもLeakageを如何に活用するかを焦点として参加者がスコアを伸ばしてしまうのでコンペとしての面白みやホストの目的も形骸化してしまいます。
Dはあまり賞金ありコンペでは見られませんが、タスクがシンプルすぎる(出来ることがない)ためあまり学びのないコンペになりがちです。例えばよくplaygroundで設定されているflower classificationなどは特段やることがなく、アンサンブルゲー+運ゲーになってしまいがちです。
どうしたらクソ要因を減らせるのか?
それでは逆に良コンペの例を見てみましょう。
例えばatmacupでは運営が複数ベースラインを用意しある程度自らデータ解析を行いタスク難易度解析やスコア予測を行っていることが伺えます。
対戦よろしくおねがいします #atmaCup
— nekoumei (@nekoumei) 2021年10月15日
運営ベースライン超えれんかった(・ω・`) pic.twitter.com/m2a3H7llZq
少し改善!
— たかいと (@takaito0423) 2021年10月19日
だがベースラインが遠い(´・ω・)
#atmaCup pic.twitter.com/3rplnGMvy0
そのためこの段階で1)タスクに無理がないか?2)(すぐに見つかる)リークはないか?3)データ品質は適切か?といったパイプクリーニングを行うことができます。
このようにコンペを開く前にDSとデータ取得サイドで連携し、ある程度のベースラインを作ることでクソ要因の多くを取り除けるのではないかと思います。(言うは易し^^)
Shakeが大きいコンペがクソコンペか?
クソ要因Bの場合等、クソコンペでは大きいShakeが起きることがあります。一方でShakeが起きたからクソコンペ、という論調もたまにDiscussionでみますがケースによると思います。自分はShake要因が予想できたかどうか、というのが大きいと思います。例えば
- 1 PublicとPrivate分布の違いが予め示唆されている、またはそれを解くのがコンペ目的の場合。(例:Bengali、PANDAコンペ)
- 2 そもそもPublicデータが少なく、trust CVが推奨される場合(例:OSICなど医療コンペに多い)
といった場合は大きなshakeが予想され、それへの対応も分析者の力量のうちとなります。
一方でタスク設計の不味さによってShakeが起きるとクソコンペ認定されるケースが多いのかと思ってます(例:Malware、タピオカコンペ)。
クソコンペを避けるには
クソコンペは傍から見ている分には面白いですが、真面目に参加すると痛い目に会います。そのため自分でクソコンペを察し回避することも重要となります。これらは経験などによって培われますが、どうしても初心者だが良コンペを掴みたい場合は
- 1 Bestfitting特徴量
- 2 金圏GM比率
などを見ると良いです。1についてですが、強い人はデータを見る嗅覚が発達しているのでヤバそうなコンペにはあまり参加しません。そのためKaggleRanking上位のBestfitting,Diter,Psi,Guanshuoが参加しているかをみてみると良いと思います。
2についてですが、強い方が参加しているのにも関わらずLBの金圏にほとんどGMがいないコンペはShakeが起きる可能性が大きいです。こちらはクソコンペとは限りませんが、耐shake体制を取りCVの切り方を注意深く見直す事が推奨されます。
KCY2021 グランプリ候補
ようやく本題のクソコンペオブザイヤーのグランプリ候補について述べます。
また繰り返しとなりますが、本記事ではクソコンペから教訓を得るのが目的であり順位付けなどはしません。そのため挙げるコンペの順番は順不同です。
Kaggle Cassava Leaf Disease Classification(タピオカコンペ)

- arutema参加: あり
アフリカの主要な農作物であるタピオカの病気を低画質スマホカメラ映像から判別可能なAIシステムを作るー社会的インパクトの極めて高いコンペ開催に参加者は盛り上がり、結果として3900チーム以上を集めた。タスクも単純で事前コンペも開催しているから品質も大丈夫なハズ、そう信じて多くのKagglerがGPUに火を付けた。
しかし何をやってもスコアが上がらない。そして音信のないホスト。混迷と迷走の3ヶ月の後に参加者に待っていたのは盛大なshakeであった。

クソ要因
データセットの品質(特にラベリング品質)がtrain/testともに低いのが厳しいコンペでした。
ベースラインモデルの混乱行列を見てみると

とclass:0(Cassava Bacterial Blight)とclass:4(健康)のクラスが異様に精度が低いのがわかります。

特にclass0と4は取り違えやすく、目で見てもほぼ健康にしか見えない画像が病気としてラベルされておりラベリング品質が低くかったです。 Trainがノイジーなのはともかく、Testのラベルもノイジーで低品質だと正常にモデル評価することは難しく、"俺は何をやらされているんだ?"感が強かったです。 (PublicとPrivateは相関していたことからPrivateラベル品質も同様に低かったかと思います)
教訓:ラベリング仕様について固めずにデータだけ取ってしまうと低品質なデータセットが出来上がってしまう。病気と健康を分ける定量的なクライテリアを用意し、ラベリング仕様として反映するべきだった。
Leak疑惑
一位はPublic/Privateの完全優勝を達成しています。1位と2位参加者が精度向上のキーとして挙げていたのはTensorFlowHubにホストが上げていたCropNetというモデルであり、これをアンサンブルに加えることでスコアが大幅上昇したそうです。ノイジーなデータでこのようにモデル一つが効くことは怪しく、ホストはtestデータで学習したモデルをHubにアップロードしていたのでは?という疑惑が残りました。
RSNA-MICCAI Brain Tumor Radiogenomic Classification

- arutema参加:エアプ
RSNAコンペにクソコンペなしーそう言われるほどRSNA主催コンペは定評があり、今回もGunaxioとBestfittingが名勝負を繰り広げてくれると誰もが期待した。
しかし蓋を開けてみると早々にProbingによるLB崩壊、盛り上がらないディスカッションと暗雲が漂う。
俺達のRSNAならきっとどうにかしてくれる。。という願いも届かずPrivateは散々なshakeだった。

クソ要因
中の人変わった?という声も聞かれるくらい過去のRSNAとは打って変わった運ゲーのクソコンペであった。Discussionを見るとランダムで推論した方がEfficientNetより性能が出た*1、CV,LB,PB全てが乖離していたと言う声があり、機械学習で解けるタスクだったかという根底が怪しく、ホストのベースライン作成が疎かだった可能性がある。1位のチーム名が"I hate this competition"だったことから闇の深さが伺える(なお順位確定後にI love this competitionに変わった)。
RNSAコンペクソコンペだったのか…このDiscussionがお気に入り過ぎて今見ても笑ってしまう(最下位の結果を逆転させると1位になるよDiscussion)。https://t.co/deIRvzzedr https://t.co/YoBmpWnxri
— にしもと@腸内細菌 (@nishimoto_gut) 2021年12月12日
画像データを使ったレモンの外観分類(レモンコンペ)

我ら日本国が誇るコンペサイトSignateから通称レモンコンペが堂々のエントリーを果たした。
ルールにあるアンサンブル禁止令に若干の不安と炎上を挟みつつもレモンの品質等級検知という社会実装であり注目度も高く、賞品のレモン10kg欲しさに大勢の参加者が集まった。
しかし初日から評価指標がQuadratic WeightedKappaにも関わらず0.99を叩き出すぶっ壊れ具合と運営の明後日に向いた回答でTwitterは大荒れ。一夜にして時のコンペになった。
クソ要因
レモンコンペまとめ
— onodera (@0verfit) 2021年2月2日
1. 開始以前にアンサンブル禁止のお気持ちルールが周知され、アンサンブルの定義をめぐり議論になる
2. testにtrainと同じレモンが含まれている事が発覚し、完答する人が出現
3. リークを指摘されるが運営は「皆さん優秀ですね」という明後日の方向のコメントを出す←今ここ https://t.co/JIZooKife8
QWKで0.99..を出すのはいくら問題が簡単でも難しく、リークが原因だった。
リーク内容
配布されたデータは同一レモンを異なる角度で撮影したものが使い回されており、更に同じレモンがtrainとtestに跨って使用されており過度に精度が出る要因となった。また配布データ名も乱数化されておらず日時データのままだったため、ファイル名を降順に並べることでtestにおけるレモンのラベルをtrainデータから容易に類推することができた。(更に撮影時間でラベル情報を区切っていたため、レモンを見ずにファイル名から完璧にラベルを推定できることが参加者から報告された)
一方でこのようなリークは失敗事例であると同時にビジネス界では共有されない貴重なノウハウであると思います。ここまで詳しく書いているのもホストを叩く意味ではなく、事例から学ぶためです。
一度でもスタッフ側でベースラインを作っていたら予防できた事態なのではないか、と傍から見ていて思いました。また農作物といったデータは集めるのが大変なので少数データ収集→データ分析上問題ないかDSサイドでベースラインを作りリーク、タスク難易度確認→本格的にデータ収集といくつかのフェーズに分け収集側とDS側でコミュニケーションを取りつつプロジェクトを進めないと後々大変な事態になるな、とも感じました。
trainデータをtestに含めては行けないという原理原則、そしてデータセットの作成には気をつけないと大変なことになる等様々な酸っぱい教訓をレモンコンペは俺達に教えてくれました。
その後
結局trainデータはそのままに、testデータはリークをなくしたものを再収集しそちらで評価するという手はずになった。運営の対応は(初動はアレにせよ)誠実で他2つと比べ参加者とのコミュニケーションは取れていました。しかし等級分類よりもtrainに存在するリークを如何にして無くすかというのが高得点を取る主眼となってしまい、参加者が本質のタスクに集中できなかったため(また開催前に初歩的なリークを見破れなかった残念さもあり)KCYに入れました。
レモンコンペのステージ2、照明変化の影響を受けてTopスコアでもPoCを下回るレベルまで精度が落ちている
— Bezilla (@bezilla1) 2021年4月1日
リーク云々もあったけど、モデル性能をつめる前に肝心のデータ取りの部分をしっかりつめないと課題解決はできないってことを示した結果なんだと思う pic.twitter.com/SFS4OkObOT
(追記:アップデートされたTestデータの色味が大幅に違ったようです。こちらのブログに詳しくまとまっております。)
レモンコンペはこんぐらい色違うねんというのもみんなに知ってほしいhttps://t.co/3Hj9kgSywE https://t.co/A4aTte1gIr
— アシノ (@ashi__no) 2021年12月12日
CPUとGPUのマルチスレッディングの違いについて
"Locality is efficiency, Efficiency is power, Power is performance, Performance is King", Bill Dally
マルチスレッディングとは?
CPUとGPUのマルチスレッディングの違いをブログにまとめていたけど例によって誰も興味なさそう
— arutema47 (@arutema47) 2021年8月16日
つぶやいたら読みたい方が多そうだったので完成させました。
マルチスレッディングとはメモリ遅延を隠蔽しスループットを上げるハードウェアのテクニックです。
ただCPUとGPUで使われ方がかなり異なるため、その違いについて考えてみる記事です。
(SIMDについて並列プログラミングの観点から触れるべきでしたが、時間無いマルチスレッディングに注目するため初版では省きました。)
本記事について
本記事はCPUとGPUにおけるマルチスレッディングの違いを出来るだけ平易に説明する。
そもそもメモリ遅延とはなにかから始めそれを減らすテクニックについて触れたあとにCPUのマルチスレッディングについて説明。
最後にGPUのマルチスレッディングについて説明し、実際のCUDAコードでどう活用されるか見る。
本記事の想定読者はハードウェアやCSに専門性がない方である。並列プログラミングやHWの専門性を持つ方にとっては教科書レベルの内容で退屈だと思う。
(追記:本記事はコンピュータアーキテクチャ的目線で書かれており、隣接分野から見ると言葉の定義が怪しいかもしれません。随時改定し語弊を減らしていきたいと思います)
tl;dr
(追記)
メモリ遅延を隠すためにCPUではマルチスレッディングが活用されてきた。一方でCPUの主目的はレイテンシを削減することであり、それら機能とのバランス上、スレッド数を大きく増やすことはできなかった。
対照的にGPUはCPU機能を削減し、スループットを最大化するアーキテクチャ。
GPUは大量のマルチスレッディングを行うことで非常に高いスループットが得られ、それは画像処理、科学計算、深層学習に好適。
メモリ遅延とは?
まずメモリ遅延(memory latency)とはなんだろう?
文字通りデータをメモリに読みに行く待機時間でコンピューティングには重要なもの。
Googleの神ことJeff Deanがよく言っている"Latency Numbers Every Programmer Should Know"にメモリ遅延の概算値が載っているのでみてみよう。
L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns 14x L1 cache Mutex lock/unlock 25 ns Main memory reference 100 ns 20x L2 cache, 200x L1 cache Compress 1K bytes with Zippy 3,000 ns 3 us Send 1K bytes over 1 Gbps network 10,000 ns 10 us Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD Read 1 MB sequentially from memory 250,000 ns 250 us
https://gist.github.com/jboner/2841832
要するにCPU外からデータを読み込むとすごく(100-1000倍)くらい遅いよ、といっている。
このCPU内メモリ(キャッシュ)からデータを読める(読む)ことをキャッシュヒット、メインメモリ(DRAM)からデータを読まないといけないことをキャッシュミスと言う。

L1キャッシュに対しキャッシュミス(DRAM読み出し)は200倍遅いのでCPUの仕事イメージ的には図のようにほぼメモリ読み出しを待っている状態になる。 これはストール(stall)と呼ばれ、CPUは何もしていない待機状態になってしまう。
メモリ遅延を減らすテクニック
このようなメモリ遅延(メモリ読み出しの待機時間)を減らし、CPUにより多くの仕事をしてもらうために色々な技術が考え出された。
キャッシュの階層化、大容量化
プリフェッチ、分岐予測、投機的実行
マルチスレッディング
キャッシュ
キャッシュの大容量化はメモリ遅延を減らす一番ストレートかつ効果的なアプローチ。 大きいは正義。
なのでCPUは世代が進むごとにキャッシュをどんどん大きくする。
半導体屋さん的にもキャッシュの性能向上・拡大は至上命題であり、最新CMOSプロセスがランチされる際には一番最初にキャッシュ性能(SRAMセル性能)が学会で報告される。今だと3nmプロセスですね。
プリフェッチ、分岐予測、投機的実行

またプリフェッチといって将来読まれるであろうデータを予め読み込む強力なテクニックがある。
図のように計算Aの次に必要となるデータBをデータAと同時に読み込むことで、計算Bを遅延なく開始することができる。(正確に予測できれば)メモリ遅延を大幅に減らしCPUの仕事効率を大きく改善する。
実際にデータBのメモリ遅延はなくしたわけではありませんが、プロセッサから見るとあたかもメモリ遅延がなくなったように見えるためメモリ遅延を隠蔽する(hiding memory latency)といったりする。

イメージとしてプリフェッチは必要となるデータを先読みする命令を追加し、予めキャッシュに格納する。
プリフェッチには次に必要となるデータと命令を正確に予測する必要がある。このような命令予測技術を分岐予測や投機的実行といってCPU分野で大きく発展してきた。
余談だが投機的実行はGoogleが発見したx86 CPUの脆弱性であるSpectreやMeltdownで話題になった機能。ものすごく平易に言うと投機的実行のプリフェッチ時に本来権限がないメモリ領域にアクセスできてしまい、悪用すると機密データへアプリケーションがアクセスできてしまう。結局Spectreを完全に抑えるには投機的実行を一部無効化するしかなく、OSアップデートで一部アプリケーションが大きく低速化したのが話題になった。ハードウェア脆弱性はコンピューティングの本質と向き合うものが多く、調べると面白いです(DRAMの脆弱性をつくrowhammerとか)
CPUのマルチスレッディング
(追記:はてブにて演算器を共用する同時マルチスレッディングとメモリ隠蔽するマルチスレッディングの話が混ざっているという指摘がありました。仰る通りなので補足・改定します。)
それではようやく本題のマルチスレッディングについて説明する。
CPUコア(物理的に存在するコア)を2倍に見せる技術がマルチスレッディング。

図の通り自分のCPU(Ryzen4800)は物理的に8コアですが、マルチスレッディングにより16コア(論理プレセッサ数)とコンピュータは認識する。

図のようにマルチスレッディングを使うCPUコアは2つに見える(コアAとコアB)。
コアAが計算、データ読み込みと動作するときにキャッシュミスが発生したとします。そうすると前述したように大きなメモリ遅延が発生し、CPUはストールし待機状態に入ってしまう。
そこでマルチスレッドCPUはプロセススイッチと呼ばれる動作が入り、コアBの命令動作に移行します。コアBが計算している間、コアAはデータを待っているため結果的に1つの物理CPUコアを有効活用できる。
また同様にコアBでもキャッシュミスが生じると今度はコアAにプロセススイッチし、データが届き次第計算を開始する。
このようにCPUのマルチスレッディングは生じてしまったメモリ遅延の裏側で別の命令・計算を行うことで、あたかも2つのコアがあるかのように見せかける技術だ。
上記がマルチスレッディングの重要な意義であり、それはCPUもGPUも変わらない。
またマルチスレッディングによりレイテンシは変わらないが、スループットを大幅に向上することが可能だ。
(補足:上記例では並列プログラミングの観点からマルチスレッディングの単純な例を書きました。実際のCPUでは同時マルチスレッディング(SMT)というもっと複雑な技術が使用されています。上記ではメモリ遅延を隠蔽する効果でしたが、SMTではCPU内のある処理で使用していない演算器を別スレッドでも利用することで更にハードウェア利用効率を高めています。こちらはメモリ遅延を緩和する効果はありませんが、タスクが演算律速である場合は高速化に寄与します。)
レイテンシとスループット

レイテンシとスループットという概念は重要でそれぞれどう改善されるか理解しておこう。
レイテンシとはある命令が実行されてから完了するまでにかかった時間。例えば命令Aが終了するまでにかかる時間をレイテンシとして評価する。これはマルチスレッディングによっては改善しないが、分岐予測で上手くメモリ遅延を隠蔽できたら改善できる。
一方でスループットとは1秒間に実行した命令の量(データ量)を表す。例えば図のように計算が1bitで全部で1秒かかったとすると4bit/sのように表す。
スループットはマルチスレッディングを活用することで大きく改善でき、更にスレッド数を増やしても改善できることがわかる。 だが後述するようにCPUは分岐予測、SMTに加え多種多様の命令を実現するためパイプラインが複雑でスレッド数をこれ以上増やしてもあまりリターンが得られない事が知られている。
では分岐予測や煩雑なx86命令などスループット改善に邪魔な機能()を全て取っ払ってマルチスレッド数を増やしまくったら最速プロセッサが作れる!という発想で発展してきたのがGPUだ。
GPUのマルチスレッディング
GPUマルチスレッディングの基本思想
CPUのジョブ(OS等)は基本的に逐次的であり、ジョブのレイテンシを最適化することを目標に設計されている。そのため非常に複雑な分岐予測機を持っており、マルチスレッド数も2と小さく抑えられている。
一方でGPUはそもそもレイテンシは全く気にせず、スループットを最大化するシステム思想。根本からCPUの設計思想と異なることを意識する必要がある。
前のCPUでは各コアにジョブを分割していたが、GPU(CUDA)ではスレッドで命令を分割するマルチスレッドプログラミングを行う。

(参考:CS15-418)
ここではスレッドが4つあるGPUコアを考える。まずスレッド0が計算を始めるがストールが発生するとする。するとメモリ遅延が生じ、プロセススイッチによりスレッド1に切り替える。スレッド1も同様にストールが発生すると次はスレッド2に。。とプロセススイッチを繰り返す。
最後にスレッド3もストールすると今度はスレッド0のデータ読み出しが完了したためスレッド0にスイッチし計算を完了させる。そしてデータが到着したスレッドに順々に切り替え、計算を行っていく。
マルチスレッディング動作自体はCPUとほぼ変わらない(ストールしたらプロセススイッチを行う)。しかしCPUと違いGPUの計算機構成が単純であるため多くのスレッドを展開可能なことが特徴である(GPUはキャッシュはあるが分岐予測は持たない)。CUDAでは256スレッドまでプログラマは定義することができ、2スレッドしかないCPUと大きく異る。
ここで注目するべきことは
プロセッサの(計算器)使用率は非常に高い(ほぼ100%)である
メモリ遅延が発生しているにも関わらず、その影響をほぼ受けていない。
の2点である。
この例ではストールが発生してもすぐにデータがキャッシュに格納されているスレッドがあると仮定したため、ほぼプロセッサは100%計算を実施することができた。 これは非常に計算機の利用効率が高く、プロセッサの理論スループット近く出せていることを示している。繰り返しになるが、マルチスレッド数が多ければ多いほどシステムスループットは改善でき、GPUはスループットを最大化するように設計されている。
また1点目が達成できている理由は、マルチスレッディングによって上手くメモリ遅延を隠蔽できているからだ。スレッド0がストールしている間に他スレッドが計算を行うことでプロセッサの計算機は動き続けることができる。
このスループット最大化処理方法はOSなどのシステムを走らせるには向かないが、科学計算、画像、ディープラーニングといった大量の計算が要求されるアプリケーションと相性が良い。
上記の考察によりGPUのハードウェア構造も見えてきたのではないだろうか? GPUのようなスループット最大化システム(throughput oriented systems)は複数スレッドを一度に展開し多数のデータフェッチを実施し、データの準備ができたスレッドから片っ端に計算する。そのためデータフェッチ機能は大量に必要で、プロセススイッチ機構などもCPUより複雑になる。
GPUのコア構造

それでは単純化したGPUのコア(SM core)をみてみよう。
マルチスレッド管理をプログラマにやらせると煩雑すぎて死んでしまう。
そのためスレッド管理はGPUではコア内にスケジューラをもたせており、ハードウェアがスレッドのスケジュールを管理してくれる。このマルチスレッドスケジューラを備えている点がGPUの固有な点であるため取り上げた。
命令セットプールにはそのコアに割り当てられた命令がプールされている。そしてWarpスケジューラが上記の例で示したように、スレッドがストールしたらデータがフェッチできているスレッドに切り替えるというスケジューリングを行う(実際のスレッド管理はブロック毎になっているが基本概念は同じ)。
CUDAコードを読んでみよう
それでは最後にCUDAコードを読んでみてGPUのマルチスレッディングについて理解を深めよう。
CUDAのHello World的なコードを読んで見る。
#include <stdio.h> __global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i]; } int main(void) { //ベクトル定義 int N = 1<<20; // 100万 float *x, *y, *d_x, *d_y; x = (float*)malloc(N*sizeof(float)); y = (float*)malloc(N*sizeof(float)); cudaMalloc(&d_x, N*sizeof(float)); cudaMalloc(&d_y, N*sizeof(float)); for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } //GPUへ配列をコピー cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice); // 計算の実行 saxpy<<<(N+255)/256, 256>>>(N, 2.0f, d_x, d_y); // 出力をコピー、メモリ開放 cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost); float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = max(maxError, abs(y[i]-4.0f)); printf("Max error: %f\n", maxError); cudaFree(d_x); cudaFree(d_y); free(x); free(y); }
SAXPYとは“Single-precision A*X Plus Y”の略でベクトル掛け算、足し算の並列化しやすい計算である。
saxpy<<<(N+255)/256, 256>>>(N, 2.0, d_x, d_y);
が本コードにおける肝であり、<<< >>>に囲まれた変数がマルチスレッド並列化を指定している。
<<<** 合計スレッドブロック数, 並列化するスレッド数>>>
と定義している。256スレッドが一塊となり、N=100万のため、それが約4000ブロック生成されるというイメージである。
GPUのコア1つで256スレッド扱えるため、スレッド数は256から増やすとどんどん高速化できそうだ。
CUDAプログラミングでは通常のC-likeプログラミングに加え並列化するスレッド数とスレッドブロック数を定義する必要があることを覚えておければ良い
またこれさえ定義すればGPU内部でコアでのスケジューリングを行ってくれるため、プログラマの労力は(比較的)小さい。(最適化するのは大変だけど。。
備考:いろいろな並列性
TBD(気になったらデータレベル並列性、SIMD、スレッドレベル並列性でググってみてください)
参考: speakerdeck.com
https://kaityo256.github.io/sevendayshpc/day7/index.html
参考文献
CMU Parallel Computer Architecture and Programming(修士1年生向けに並列プログラミングを教える入門講義です。神講義。)
Computer Architecture: A Quantitative Approach(3章にスレッドレベル並列性について、4章にGPU並列性について詳しく書いてあります。是非一読を)
How many threads can run on a GPU?
このようにスループットを最大化した際には今度はメモリ帯域が性能律速に関わってきます。"メモリ律速"については以下記事で詳しく記述しています。
入門書籍
CPUの創り方安くなってるhttps://t.co/Ly5Sxsiaju
— arutema47 (@arutema47) 2021年8月25日
個人的にCPU勉強するにはハリスがおすすめです。セールじゃないけどhttps://t.co/Fp27Wca2ej
— arutema47 (@arutema47) 2021年8月25日
KagglePC、サーバー構成メモ
Kaggleマシンの参考になればと思い執筆しました。
最近はColab Proが月1000円と破格でディープラーニング環境を提供しており、Kaggle Notebookも相当良いです。
感覚的にですが、30万くらいのマシンを組むよりはColab Pro、Kaggle Notebookの方が早く、それ以上払うならばリターンが得られるというイメージがあります。
さらに月5000円のColabPro+だとV100マシンが優先的に使用できるため50万くらいのマシン相当になります。高いかなーと当初思いましたが電気代を考えるとオンプレV100マシンを回すより安いです。
自分は開発はオンプレ鯖で行ってアンサンブル学習はColabを使用して並列で学習したりします。
オンプレマシンのメリットとしては
容量をかなり大きくできる。2TBなど扱えるのは大きく、コンペによっては大規模データが必須となるためオンプレが有利になる。
学習が打ち切られないため一週間など長期間回せる
環境をカスタマイズできる。
オンプレマシンのデメリットとしては
排熱、音が凄い。夏場など厳しい。家族の理解が必要。
電気代が高い。5000円は軽く超える。うちはGPU一枚で一万円くらいかな。。
場所を食う。
省スペース構成
自宅のkaggleサーバーは5年前に組んだゲーミングPCにubuntuを入れて継ぎ足し継ぎ足し改造してます。

個人的には自宅用鯖は上記のような小さいケース(mini-ATX, ITX)で組みたいという謎のこだわりがあり、拡張性がほぼないです。ケースファンがしっかりしていればGPUで300W一週間ぶん回してもミニケースで放熱いけちゃいます。
省スペースに組みたいならばこのような1GPU構成がおすすめですが、タワーケースをおいてもいいよ、という方ならばこの構成はおすすめしません。
【CPU】AMD Ryzen 5 3600X BOX ¥29,976 @最安
【メモリ】CFD CFD Selection W4U2666CM-16GR [DDR4 PC4-21300 16GB 2枚組] ¥14,976 @最安
【マザーボード】ASRock B550M-ITX/ac ¥15,970 @最安
【GPU】お好きなものをどうぞ
【SSD】サムスン 870 EVO MZ-77E2T0B/IT ¥26,980 @最安
【電源】ANTEC NeoECO Gold NE750G ¥9,990 @最安
【合計】 97,892円
メモ
GPUがどう考えても一番高いので予算にあったお好みのものでどうぞ。
GPUは3080ti,3090,2080ti,RTXtitan あたりで十分戦えるかと思います。
メモリは16GBあれば(画像+Swapを使えば)十分足りる感じです。またCPUはRyzen5以上ならば問題なし。
SSD容量は大事です。ケチらずに2TBを買いましょう。
HDDは遅いので絶対ダメ。
今パーツ高いですね。。
タワーPC構成

Kaggleするわけではないですが、お仕事用にはタワーPCで組んでました。デカいです。
【CPU】AMD Ryzen 7 3700X BOX ¥35,287 @最安
【メモリ】CFD CFD Selection W4U2666CM-16GR [DDR4 PC4-21300 16GB 2枚組] ¥14,976 @最安
【マザーボード】ASRock B550 Taichi ¥32,890 @最安
【SSD】サムスン 870 EVO MZ-77E2T0B/IT ¥26,980 @最安
【GPU】お好きなものをどうぞ
【電源】Corsair HX1000 CP-9020139-JP ¥26,378 @最安
【合計】¥ 136,511
メモ
これにtitan*2をぶっ刺していました。あちちです。
GPU*2まで対応してます。PCIe16xが3個ついてるRyzen用マザーはこれとかあります
論文執筆・研究活動に参考になるページ
論文の書き方
あのAIで有名な松尾先生の論文の書き方に関するページ。
論文のストーリー構築の重要さからproof-readingに関する心構えまで全て参考になる。
Stanford大のJennifer WidomのTips for Writing Technical Papersを和訳したものです。
特にイントロダクションを書く際に考える5つのポイント:
問題は何か?
なぜその問題が興味深くかつ重要なのか?
なぜその問題を解くのが困難なのか? (例:なぜ単純なアプローチではうまく解けないのか?)
なぜ今までその問題は解決されてこなかったのか? (もしくは,既存手法の何が悪いのか?提案手法と既存手法との差異は何か?)
提案アプローチの重要な要素は何か?それを用いた結果はどうだったのか? 特定の制約条件についても全て述べるようにすること.
をまず考える、という思考フレームワークは勉強になります。
研究の取り組み方
How to Have a Bad Career in Research/Academia

How to Have a Bad Career in Research/Academia
チューリング賞を受賞したPatterson先生の反例を元に良い研究の取り組み方について話した有名な講演。
How to Have a Bad Career | David Patterson | Talks at Google - YouTubewww.youtube.com
アップデートされた内容がこちら。
Do grades matter?
スタンフォードのFatahalian先生の大学院生の過ごし方について。
ハードウェア論文の書き方
How to write a good Journal of Solid State Circuits paper, Bram Nauta
研究ポジション応募
How to get a faculty job
ハーバード教授のMatt Welshのブログ。非常にわかりやすい。 ザッカーバーグの指導員だったからかザッカーバーグがよく例文で登場する笑
HAQ: Hardware-Aware Automated Quantization with Mixed Precision
HAQ: Hardware-Aware Automated Quantization with Mixed Precision (CVPR 2019 oral), Kuan Wang∗, Zhijian Liu∗,Yujun Lin∗, Ji Lin, and Song Han
課題
量子化はDNNをモバイルデバイスの高速化において重要な技術だが、各レイヤのビット幅などの設計は今まで手設計でルールベースなどで行われてきた。この論文ではレイヤ毎の量子化ビット数を自動的にハードウェアの性能を反映しつつ決定可能なHAQ技術を提案する。具体的には強化学習エージェントを使うことでレイテンシを最小化するパラメータを求める。
提案技術
mixed precision
DNNの量子化は幅広く使用されている技術であり、一般的には量子化はDNNの全レイヤを単一のビット幅になるよう圧縮を掛けてしまう。
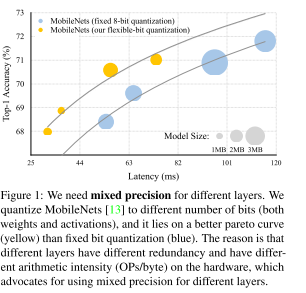
一方でDNNはレイヤごとに冗長性や演算密度が異なり、レイヤ毎に量子化ビット数を最適化した方が性能向上が狙えるというのが発想(Fig.1)。 このようなflexible-bit qunatizationによって性能・レイテンシトレードオフを改善するというのが研究の狙い。
ハードウェア-awareな性能見積もり
 FLOPS等の指標はモデルの計算量を簡単に机上で見積もることができるため、幅広く使われている。一方でFLOPSはモバイルデバイスのレイテンシに直結しておらず、有用な指標でないことを指摘。実際はハードウェアのキャッシュサイズやメモリバンド幅などが支配的になるのでFLOPSは当てにならないことが多い。(ビットシフトは0FLOPSなので演算量はなしとした狂った論文もありましたね。。)
FLOPS等の指標はモデルの計算量を簡単に机上で見積もることができるため、幅広く使われている。一方でFLOPSはモバイルデバイスのレイテンシに直結しておらず、有用な指標でないことを指摘。実際はハードウェアのキャッシュサイズやメモリバンド幅などが支配的になるのでFLOPSは当てにならないことが多い。(ビットシフトは0FLOPSなので演算量はなしとした狂った論文もありましたね。。)
そこでHAQではRLエージェントのアクション中にハードウェアを直接盛り込むことでハードウェアレイテンシを直接観測する(Fig.2)。力技だが、HW性能見積もりをちゃんとやっているのでHardware-awareな見積もりが可能。HWは実際にはFPGAにて実装している模様。
RL agent
RLエージェント報酬はレイテンシではなく、量子化後の精度としている

リソース最小化はRLエージェントではなく、アクションスペースの制限で達成している。 簡単にいってしまうとRLエージェントが提案する量子化ビット数候補に対しリソース(レイテンシ、モデルサイズ)を計算し、もしそれが要求を満たしていなかったら各レイヤのビット幅をリソース制限を満たすまで少しずつ減らしていく。そのためRLで直接量子化ビット幅自体を最適化しているわけではない。 直感的にはターゲット精度を達成するための最適な量子化ビット数を探索するようなアルゴリズムに見える。そのためリソース制限を厳しくすることで、そのリソースで得られるベストな量子化組み合わせを探索するイメージ。
手法はかなりローテクな気がするが、リソースをRLエージェントの報酬にするよりは探索空間が狭くて上手くいくということか。
離散化アクションスペースでは量子化ビット数の大小の関係を組み込むことができないため、α=[0,1]の連続値を入力し離散ビットを出力する関数を用いて擬似的に連続的なアクションスペースを作成する。

結果
 決め打ち量子化(PACT)に対しHAQは同等のレイテンシで高精度達成。
決め打ち量子化(PACT)に対しHAQは同等のレイテンシで高精度達成。
 面白いことにモバイルデバイス向けではdepthwise convolutionのビット幅を縮小するようにしている。おそらくモバイルデバイスではdepthwise convでメモリ律速になりやすく、その点を解消しようとRLエージェントが最適化をかけていると考察。
面白いことにモバイルデバイス向けではdepthwise convolutionのビット幅を縮小するようにしている。おそらくモバイルデバイスではdepthwise convでメモリ律速になりやすく、その点を解消しようとRLエージェントが最適化をかけていると考察。
Introduction to Distance Sensors (Stereo Camera, Projection, LiDAR)
This is an English translation of
It's mostly powered by DeepL, so don't count too much on the English.
Goals
While a normal camera extracts the brightness and color of an object, a distance sensor senses the distance to an object. This is why they are sometimes called 3D cameras or depth sensors.
Knowing the distance is important in a variety of applications, for example, in automated driving, it is essential to know the exact distance to the vehicle in front. In games and other applications, Kinect, which uses distance sensors to extract human movements, has expanded the range of games. Distance sensors are also important for surgical robots such as DaVinci to know the exact distance to the affected area.
It is difficult to visualize the dimensions and distance of a room in a photograph or floor plan, but 3D mapping allows you to map the room itself. ! image.png
This kind of mapping can be easily done with the new iPhone Pro using apps like Polycam, so if you have the device, give it a try!
And the age of 3D scanners in our pockets has begun! The iPhone 12 version of Polycam is now out on the App Store https://t.co/Oih4jQTTEc! Go forth and capture your world 🚀🎥! #iPhone12Pro #iPhone12ProMax pic.twitter.com/JY8LAEi5xk
— polycam (@PolycamAI) 2020年10月23日
This article lists the major types of distance cameras in the world, their overview, features, and products used.
The goal is to help you choose the right distance sensor for your R&D project, for example. I'm a LiDAR expert, so I'm not very familiar with camera-based methods, but I've also described the most frequently used distance sensors: stereo cameras and projection cameras.
You can also read more about point cloud deep learning here: aru47.hatenablog.com
Stereo Cameras
Overview
This is a distance sensor that is widely available on the market that is used in e.g. Subaru EyeSight and other industrial products.

This WhitePaper from ensenso is also a good reference.
Obtaining Depth Information from Stereo Images Vision.pdf)

The principle is the same as how we see things in three dimensions.
If you close your eyes alternately to the left and right and look at the monitor, do you see the shift from left to right?
The brain perceives the object with the larger shift as being closer and the object with the smaller shift as being farther away. This is the principle behind stereo cameras, and it can be said that the distance sensors that we use are also based on stereo cameras**.
A stereo camera can measure the distance to an object based on how far the pixels have shifted. The farther apart the cameras are, the greater the pixel shift relative to the object, and the more accurate the distance. On the other hand, the closer the cameras are to each other, the more difficult it is to measure the distance because there is almost no pixel shift. Increasing the number of pixels will, in principle, increase the range, but the downside is that the amount of signal processing increases exponentially.
The biggest challenge for stereo cameras is to determine if the two cameras are looking at the same object. This requires advanced image processing techniques and makes it very difficult to guess whether distant objects are really identical or not.
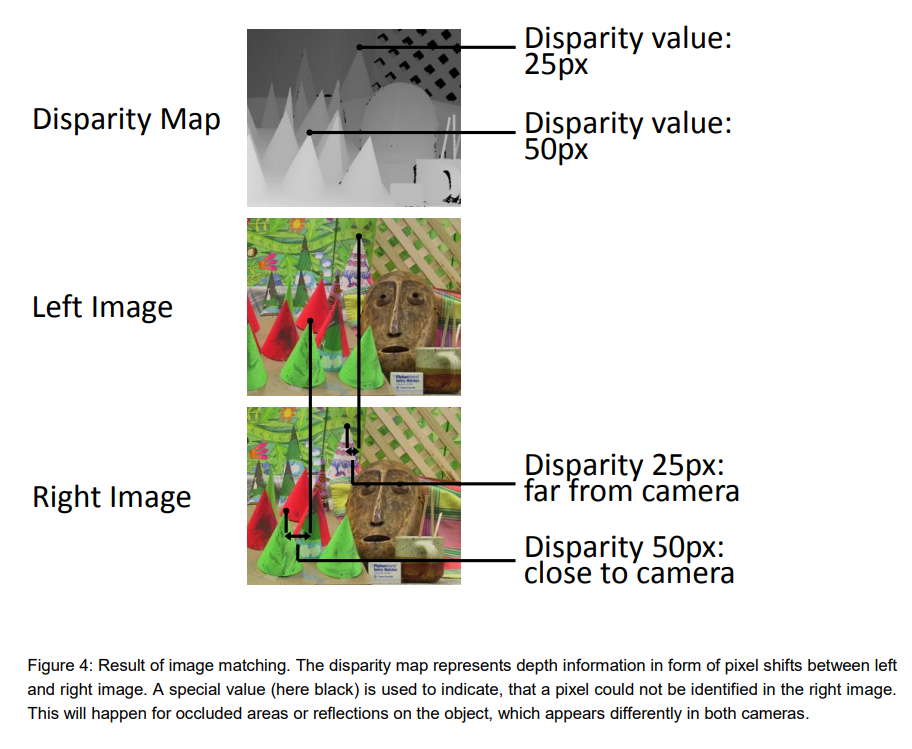
Reference: Obtaining Depth Information from Stereo Images
In addition, there must be no difference in height between the left and right images in order to adapt stereo vision. In order to adapt stereo vision, there must be no height difference between the left and right images, so pre-processing is required to remove camera distortion and calibrate (rectify) the height difference.
Features
While other distance sensors require special components (such as lasers), stereo cameras can be realized by using only two ordinary commercial cameras.
However, in order to measure the distance, the left and right cameras need to see (recognize) the same location of the same object, and it is difficult to measure the distance of distant objects. The disadvantage is that the housing becomes larger if you want to see farther**, because parallax is not created for distant objects unless the camera is set farther away like EyeSight, although the mathematical formula is omitted.
Products used.
1台の PC に4種類の RGB-D カメラをつないで同時キャプチャしてみた。左上 DepthSense DS325、右上 Kinect v2、左下 Kinect v1、右下 RealSense D435。こけて倒したのは D415 (今回は不使用)。 pic.twitter.com/n5h4P2MPZO
— 床井浩平 (@tokoik) 2019年5月30日
For commercial products, Intel's RealSense** comes with software (SDK) and is easy to try.
The RealsenseD435 can be purchased on Amazon for 24,000 yen.
Here is an example of the RealsenseD435 output.
- High accuracy can be obtained at short distances (1-3m).
- High resolution because it is camera based.
- Real-time (30FPS) operation even on a CPU
These are the features of the D435. I think it is the best choice for distance sensors for hobby use.
The RealsenseD400 series also has pattern projection, but it is mostly a stereo camera that is used for distance estimation (even if the projection is turned off, the picture remains almost the same, so it is just a supplementary function).
Pattern Projection Cameras
Overview
Pattern projection cameras are used in high-performance 3D cameras for industrial applications and iPhone FaceID.
It projects a known pattern onto an object (pattern projection) and uses signal processing to derive the distance between the camera and the object from the way it is distorted.
If you project a pattern of stripes onto an object like a helmet, you will see that the stripes are distorted depending on the height of the object. By reading and analyzing such distortions, the three-dimensional shape of the helmet can be determined.

The video below also explains how the iPhone FaceID works. It uses infrared light to emit a pattern all over the face, and is able to read the exact shape of the face. Since it sees the unevenness, it is difficult to fool FaceID, which makes the security stronger.
Compared to LiDAR, the components are simpler, so the price can be reduced.
Very high accuracy can be obtained for indoor use (mm~um accuracy).
On the other hand, outdoor use with a lot of external disturbance is difficult.
There are also many approaches that use both pattern projection and stereo vision.
Ensenso, a high-precision 3D camera often used in picking robots, provides both pattern projection and stereo vision. The advantage of this camera is that it can obtain a clean point cloud even for objects that are difficult to match, which stereo vision is not good at (for example, flat walls).
Products
iPhone
! Image result for iphone face id
FaceID is an active projection camera that is used for facial recognition on the iPhone.
Every time FaceID is used, the iPhone emits an infrared pattern.
In fact, the original technology evolved from Apple's acquisition of the company (PrimeSense) that developed the Microsoft KinectV1. It's called MiniKinect by those who know it. LOL.
Industrial Products (Ensenso, Keyence)
How to reconstruct objects with an Ensenso 3D camera and data comparison using HALCON image processing: 3D image processing detects irregularities or minimal deviations that are not even visible to human eyes. #demo #objectverification #3Dvision #qualitycontrol #industry40 pic.twitter.com/3p4EEurOUW
— IDS Imaging Development Systems GmbH (@IDS_Imaging) 2018年8月9日
There aren't many examples of industrial sensor outputs on the net, but they are mm-accurate and incomparable to Realsense (which is over-spec for hobby use).
They cost several million yen each.
They are often used for inspection in factories and for robotic products. If you go to an industrial exhibition, you'll often see one of these attached to a product, so look for it.
On the other hand, the projection can only be accurately read within a few meters, making it difficult to use outdoors. Basically, it is for indoor use.
- Keyence 3D Camera, Ensenso 3D cameras
Time of Flight LiDAR
How Time of Flight works
Camera-based distance sensors (stereo cameras, projections) and LiDAR are fundamentally different in principle.
On the one hand, LiDAR measures distance based on Time of Flight.
The principle is simple: a laser beam is emitted from the enclosure as shown in the figure below, and the time it takes for the laser to be reflected back to the object is measured. If the laser beam returns after 10 seconds and the speed of light is 1m/s for simplicity, the distance to the object is
(10s * 1m/s)/2 = 5m
and we know that the object is 5 meters away. This method of deriving the distance based on the time of flight is called Time of Flight.
Since the actual speed of light is very fast, 108m/s, the time it takes for the light to return is on the order of a few picoseconds or nanoseconds, so the circuit used to measure the time needs to be highly accurate.
The type of LiDAR which directly measures the return time of the laser pulse is also called a direct time of flight sensor. FIY, The Lidar in iPad Pro and iPhone is direct time of flight.
https://tech.nikkeibp.co.jp/atcl/nxt/column/18/00001/02023/?ST=nnm

Features
The most important features of LiDAR are
- High accuracy
- Long range
- Resistant to external disturbance (can be used outdoors)
- High price
High cost Since the distance is derived directly from the return time of a strong pulsed laser beam, it is difficult to introduce errors and is highly reliable. Since these features are difficult to achieve with a camera-based system, LiDAR is expected to be used mainly for detecting distant objects in automated driving, which is required to operate even in harsh conditions.
On the other hand, the cost of LiDAR is several to dozens of times higher than that of the camera type because it requires a scanning mechanism, laser emitter, laser receiver, and many other specialized elements.
Recently, Livox and other LiDARs costing less than $1k have begun to be mass-produced and used in many robots, so the days of being shunned because of their high price may be coming to an end.
Livox全ラインナップに対応した低速(<30km/h)Slamを公開しました。先日公開した高速SLAMはHorizonのIMU情報を使っていますが、本プログラムは点群だけで計算する汎用型です。低速AGV、マッピング、AR、VR等の開発にご利用ください。https://t.co/LKLGZYPTYA pic.twitter.com/zTnn2wYbZP
— Livox_JAPAN (@LivoxTech_JP) 2020年6月29日
The greatest advantage of LiDAR is its ability to scan a fine point cloud over a long distance (100-200m) as shown in this figure.
LiDAR is the only distance sensor that can obtain a perfect point cloud over a long distance in the open air. This is why LiDAR is expected to be very popular in automated driving. (Although some people, such as Tesla, say they do not need LiDAR...)
Scanning LiDARs
It is possible to obtain the distance per pixel using the above-mentioned time of flight principle of LiDAR. But how can we get the distance information as a picture? To do this, LiDAR has a concept of scanning.
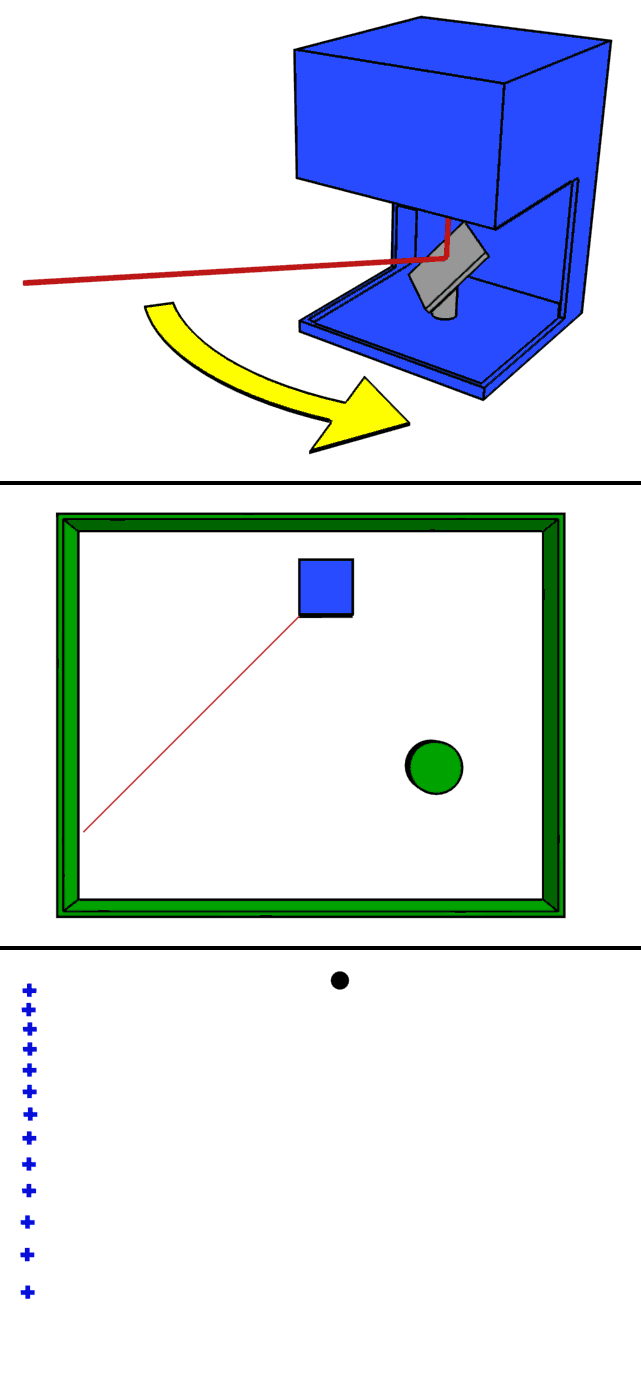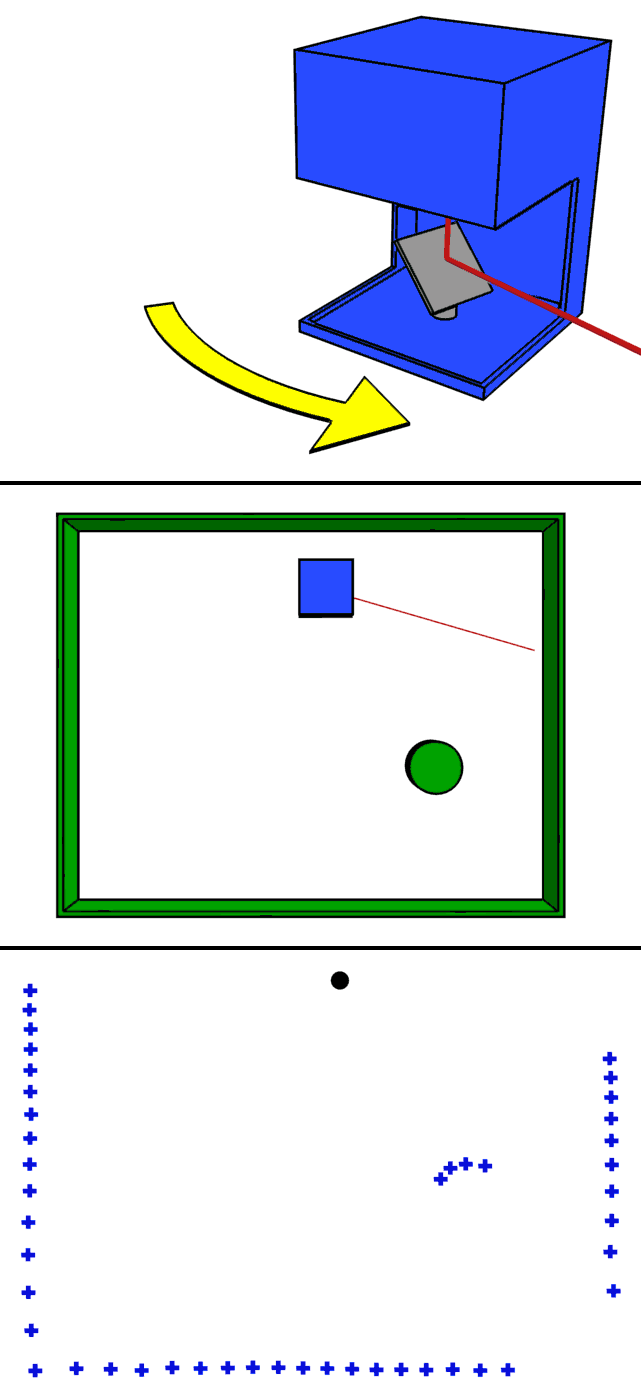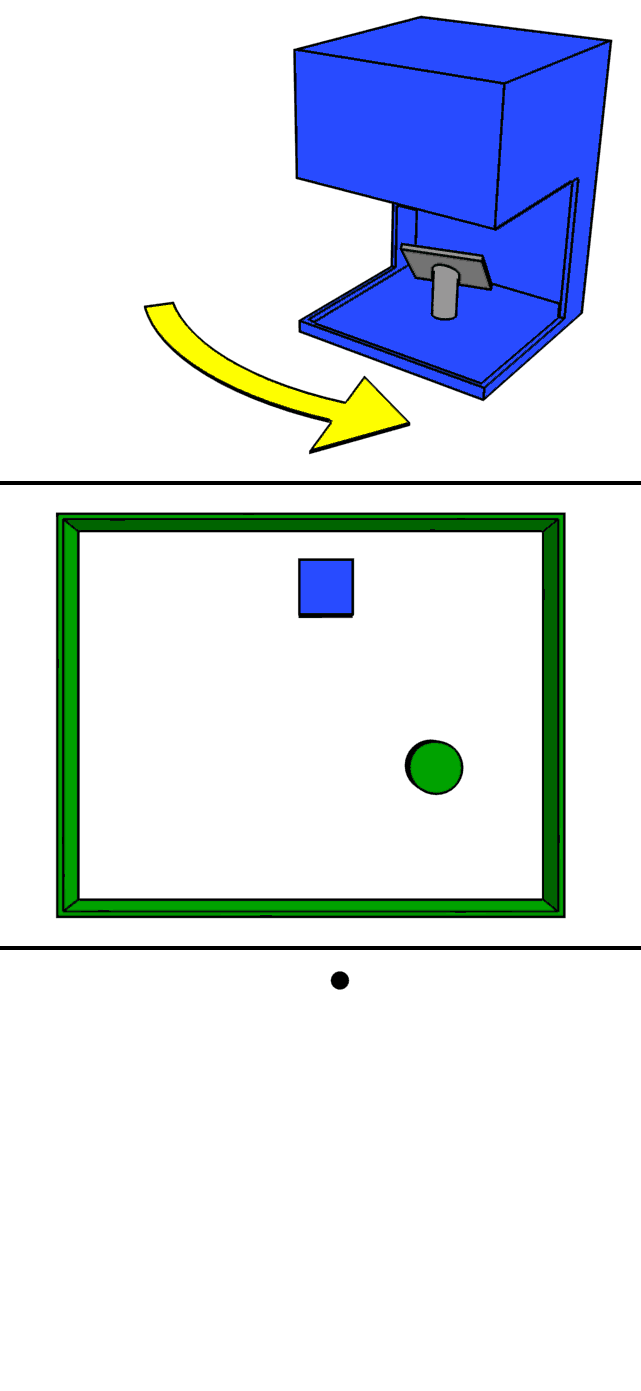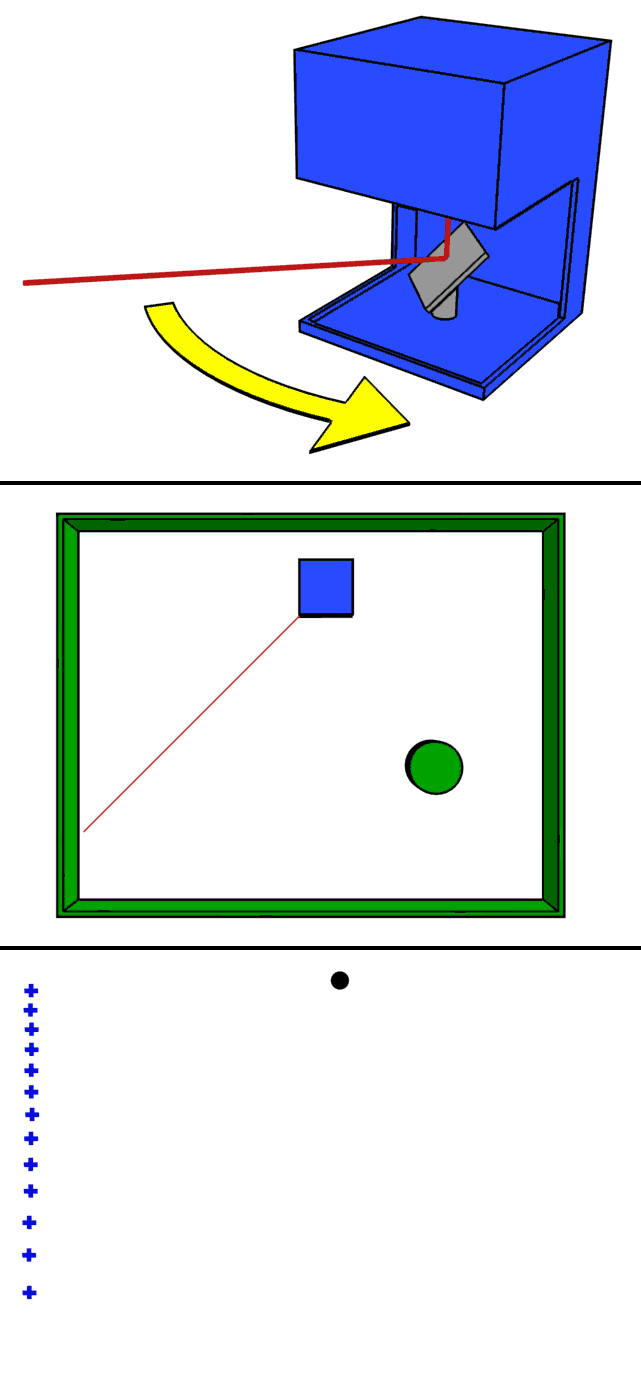
One approach is to use a mirror to scan (scan) the emitted laser beam.
{kind=link}
{kind=link}
The animation above is a clear representation of LiDAR scanning using a mirror. By rotating the mirror, the laser beam is scanned 360 degrees to obtain information on the entire surrounding environment.
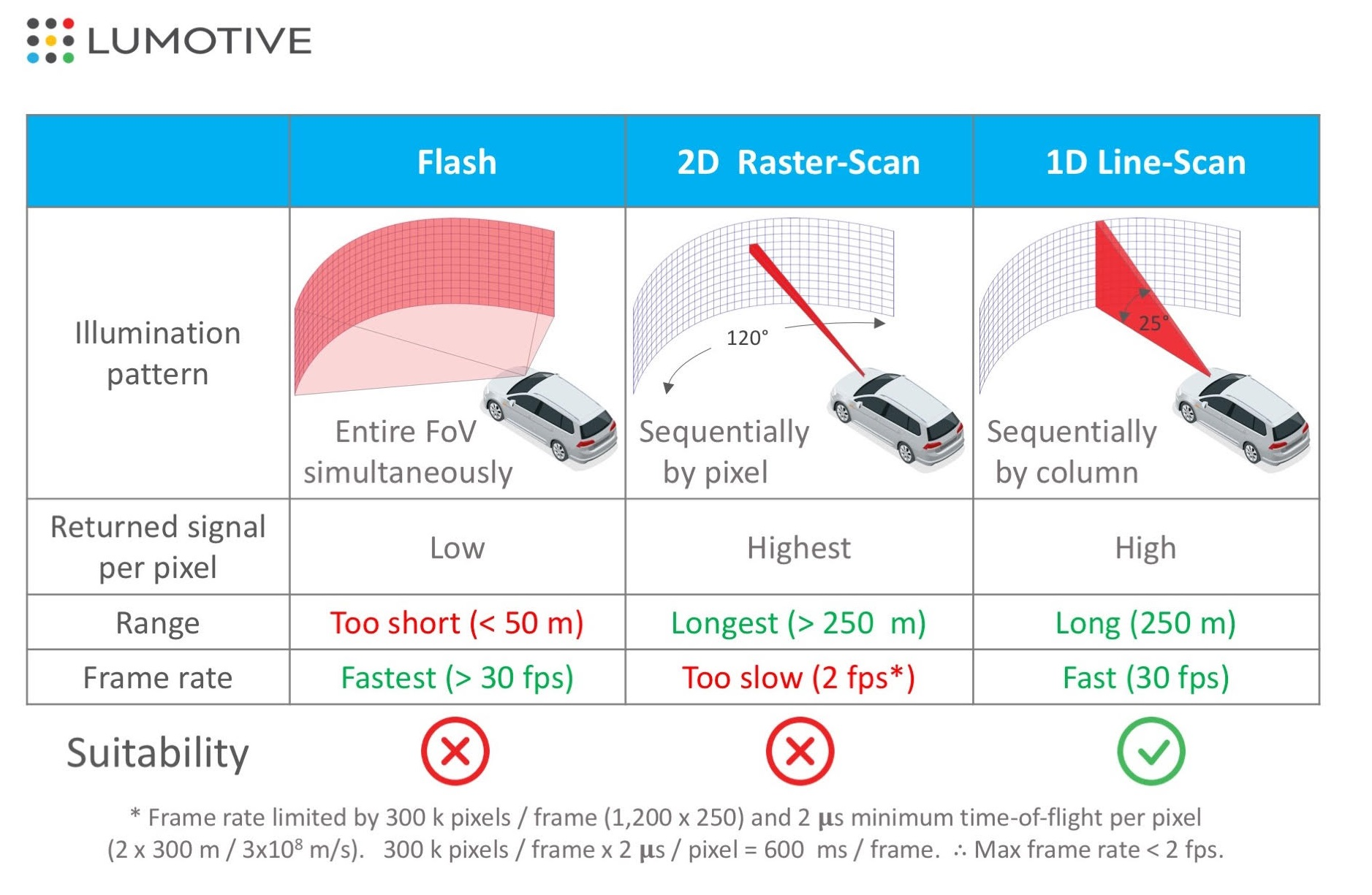
A 2D raster scan is a method of scanning two-dimensionally while acquiring information one pixel at a time, while a 1D scan is a method of scanning horizontally while acquiring vertical pixels all at once. Both methods produce distance, but the 1D scan method is more likely to achieve a higher FPS because of the shorter time required to obtain a distance image.
On the other hand, using a mirror (like a single-lens reflex camera) will increase the size of the LiDAR housing. For this reason, MEMS mirrors are being used instead of mirrors, and Optical Phased Array LiDAR, which scans optically, is being actively developed, and it is expected that LiDAR will become smaller and less expensive in the future.
Flash LiDARs
LiDAR has also been developed to acquire two-dimensional pixel information at once, just like an image sensor of a camera, without scanning. This type of LiDAR is structurally very simple, as it only emits a laser beam that covers the entire image sensor and receives the light. Therefore, it can be realized at a lower cost than the scanning type.
On the other hand, there are several issues - Short distance due to low laser power per pixel - Susceptible to external disturbance - Susceptible to interference and noise Therefore, it is not suitable for automatic driving, but it may be useful for indoor robots.
Products
Velodyne Series
The most famous ToF LiDAR products are probably those of Velodyne, the first LiDAR manufacturer to introduce LiDAR products to the world and still the reigning "king".
Their products are notorious for being very expensive, ranging from hundreds of thousands to millions, but the quality is top-notch, and the only self-driving cars that don't use Velodyne are Tesla and Waymo (Waymo uses its own LiDAR). I also imagine that Velo is often used in robotics R&D because of its high pixel count and accuracy.

Livox Horizon
Livox, a subsidiary of DJI, has released a LiDAR that achieves high accuracy while costing less than $1k, and this is becoming the mainstream for robotics projects.
You can buy them in amazon as well..
The quality is great, and the SDK is available on github, so it's easy to develop.
iPhone
 The front of the iPhone has actually been equipped with ToF LiDAR (one pixel) for quite some time.
It does not do any scanning, so it is probably low cost.
The front of the iPhone has actually been equipped with ToF LiDAR (one pixel) for quite some time.
It does not do any scanning, so it is probably low cost.
The Proximity Sensor in the image is the same. When you make a call, if you bring the iPhone screen close to your face, the screen will automatically turn off. I think this is because it senses the distance between your face and the iPhone.
Note: iPhone and iPad Pro are now equipped with dToF LiDAR.
iToF LiDAR
This technology is used in Azure Kinect and other applications.